Source code files are living things. We add new ones and change their content on daily basis. Occasionally we delete them, too. Git is amazingly efficient when it comes to tracking these kinds of changes.
However, sometimes we need to change the file name, or file path, or both. And if you are an AL developer who has ever transformed a C/AL project into AL, you have probably done this at least once, for all .al files in the project.
And this is where git may surprise you. After you rename a file, sometimes you’ll notice that git detects it as a rename. But on other occasions it will not be the case.
Let’s dive in.
A few simple examples to work from…
Take a look at this simple repo:
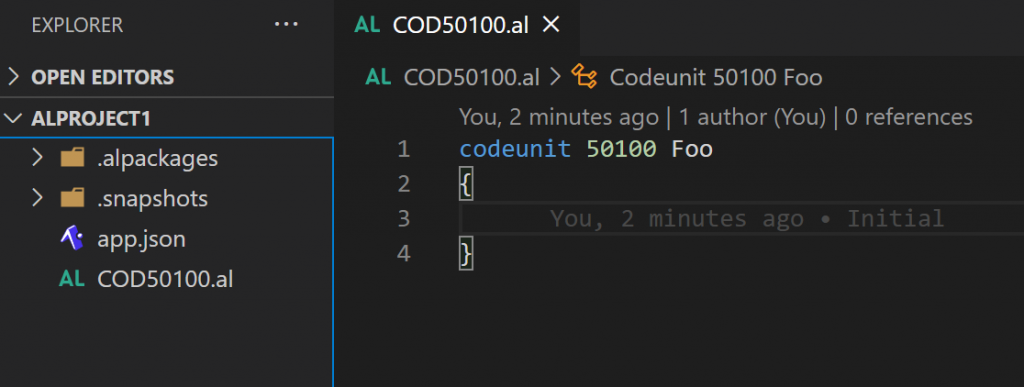
Now you decide to move this file into the right place, and you also decide to rename it in the process. So you end up with this:
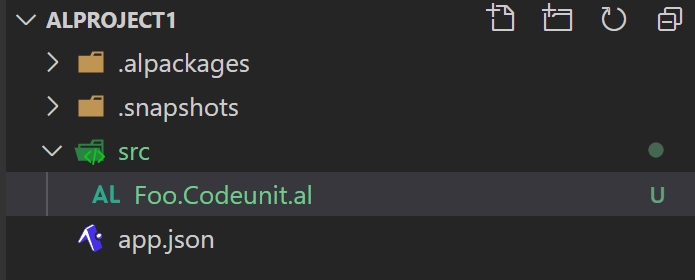
When looking in the Source Control, you see this:
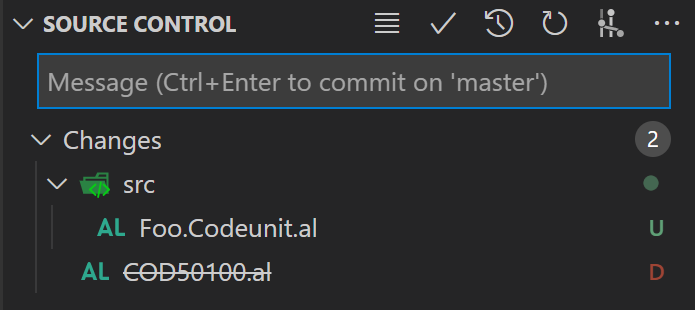
Apparently, git sees this as a deletion of .\COD50100.al and addition of .\src\Foo.Codeunit.al. This is probably not what you would have expected. Also, probably not at all what you want.
Stay calm, things are under control (so far). Stage these changes, and you get the following:
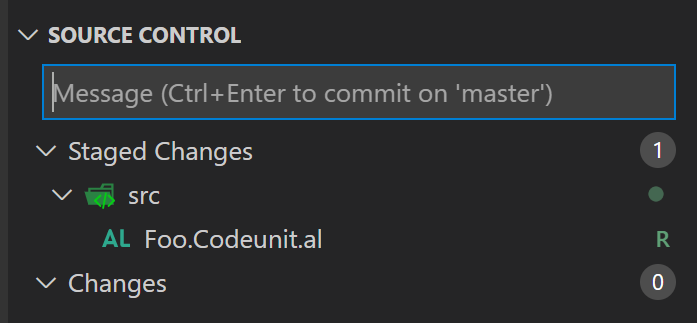
Apparently, after staging, git is suddenly able to see this as a file rename. If you commit this, and then look into file history, you’ll only see this:

Whatever happened to that initial commit? Why is it not here? Did we just lose all the previous file history? Good news is: nothing is lost (yet). It’s that git – and for a reason, and we’ll get there – doesn’t just show you all that history.
Let’s CLI this for a second:
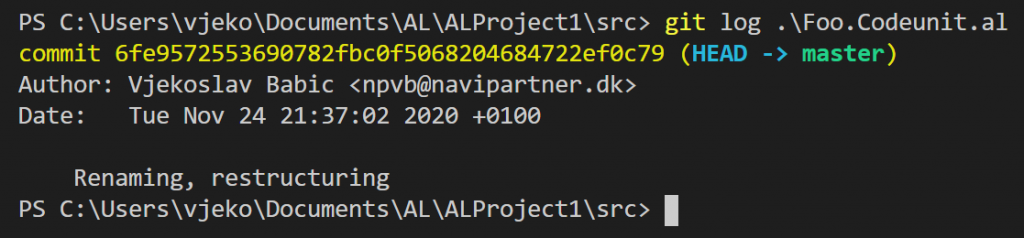
Obviously, the same results. No wonder here, it’s git log that any git GUI tool will run in the background for you, anyway.
But if you read through git log documentation, you’ll notice that it can actually follow the renames. Run this:
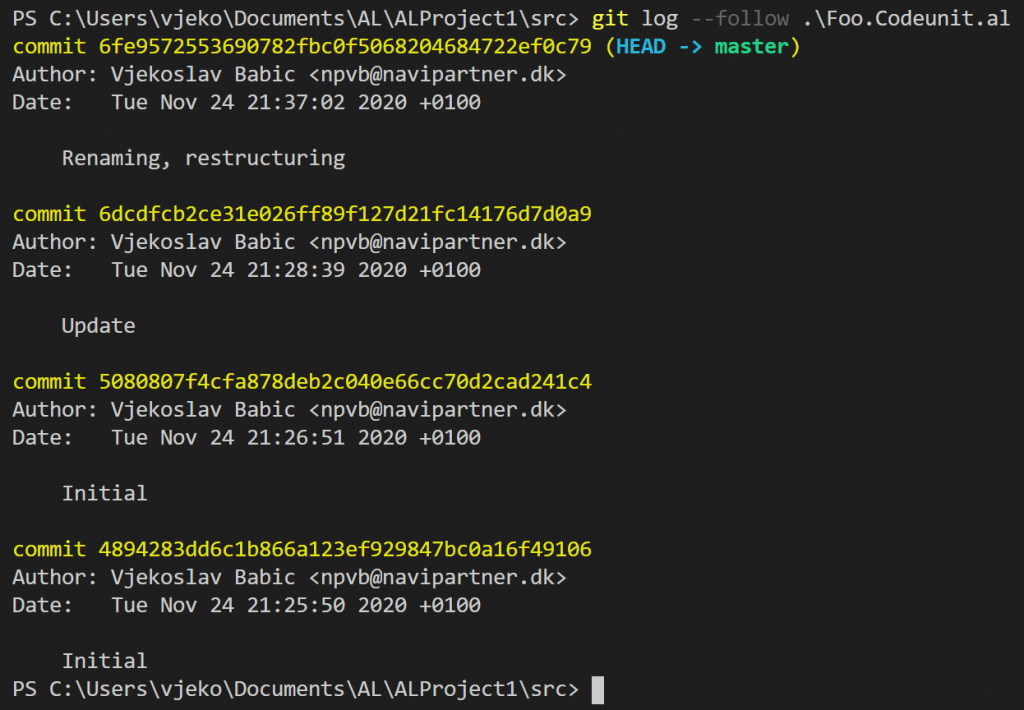
Ok, now we are talking business (except for the fact that I fumbled while preparing this demo and had to “Initial” commits, but that’s me, not git).
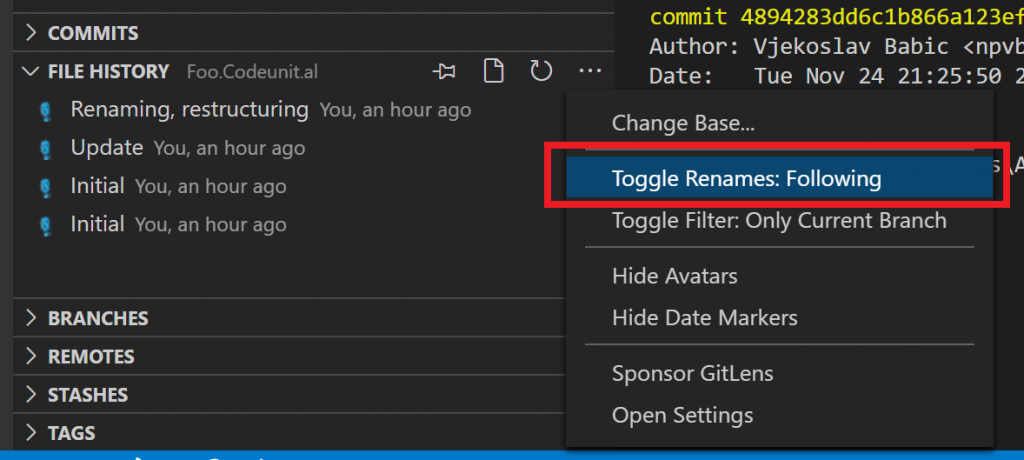
So far, we know that git doesn’t lose the history of renamed files, but by default doesn’t show it. As I said, we’ll get to the bottom of this. Depending on which tool you are using to inspect file history, there are various ways to include rename history. With VS Code, I use GitLens (you should, too!) and this is how you can tell it you want the –follow option with those git logs it issues:
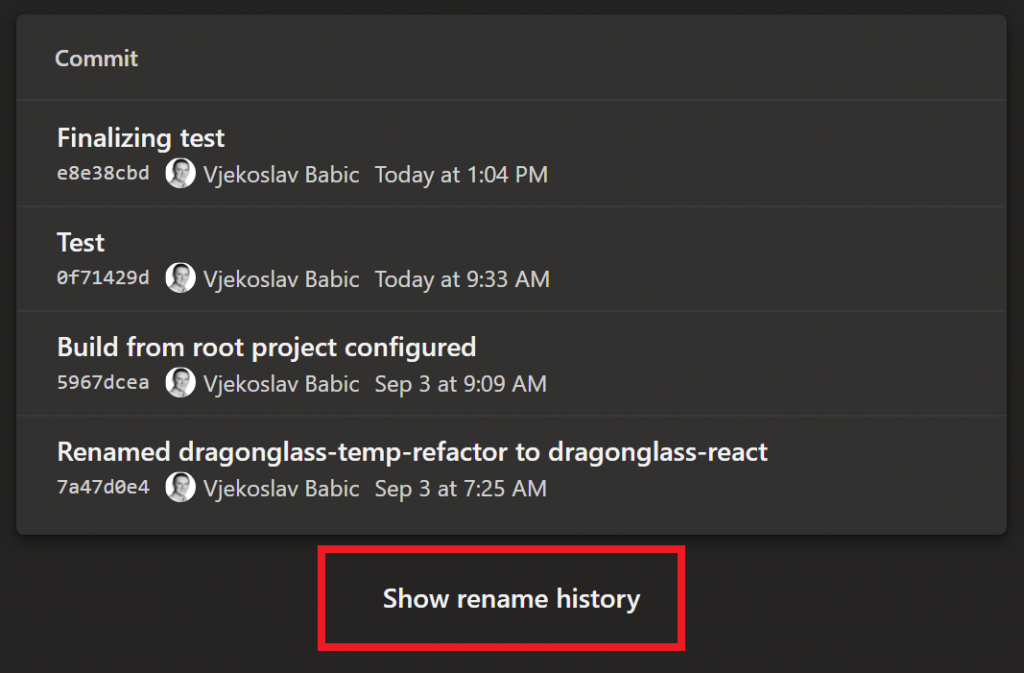
In DevOps, you’ll see this (the screenshot is not from the same repo, but it’s the “Show rename history” option that matters):
So we have our history. Nice.
Now rename Foo.al to Bar.al, and add some code in there, like this:
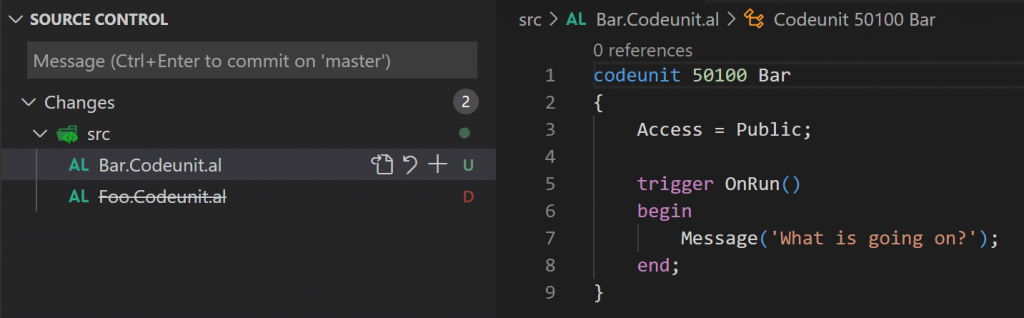
Files are not staged yet, so this is not shown as a rename. But, if you think that staging this will help, you’ll be wrong. Check this out:
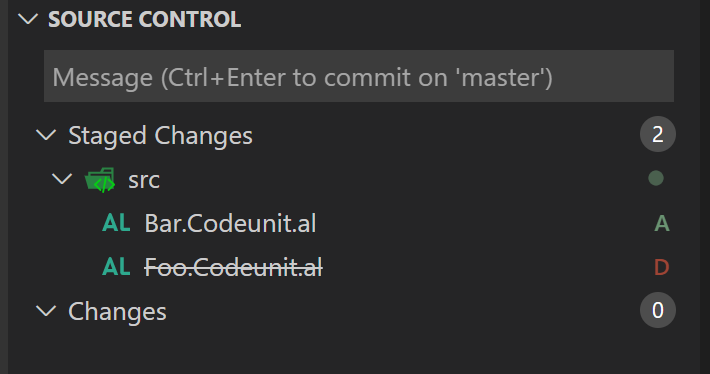
We still have a deletion and an addition. Committing won’t help either. If you try to git log –follow to verify this, you’ll see this:
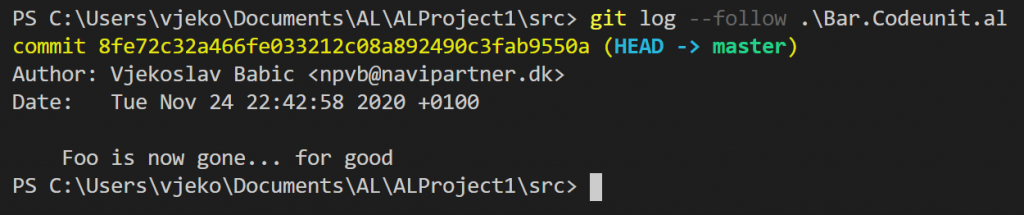
What’s going on here, really? Why was git able to follow move of .\COD50100.al to .\src\Foo.Codeunit.al, but was unable to follow the rename of .\src\Foo.Codeunit.al to .\src\Bar.Codeunit.al?
Let’s dive in deeper. A lot deeper.
Git’s opinionated view of changes
Git does not know of a concept of “change”. It only knows of “add” and “delete”. When you change a line of code, git doesn’t see it as a change in that line. Rather, it sees it as a deletion of the old line, and addition of a new line. That’s how git sees it, and that’s how it’s logged in git.
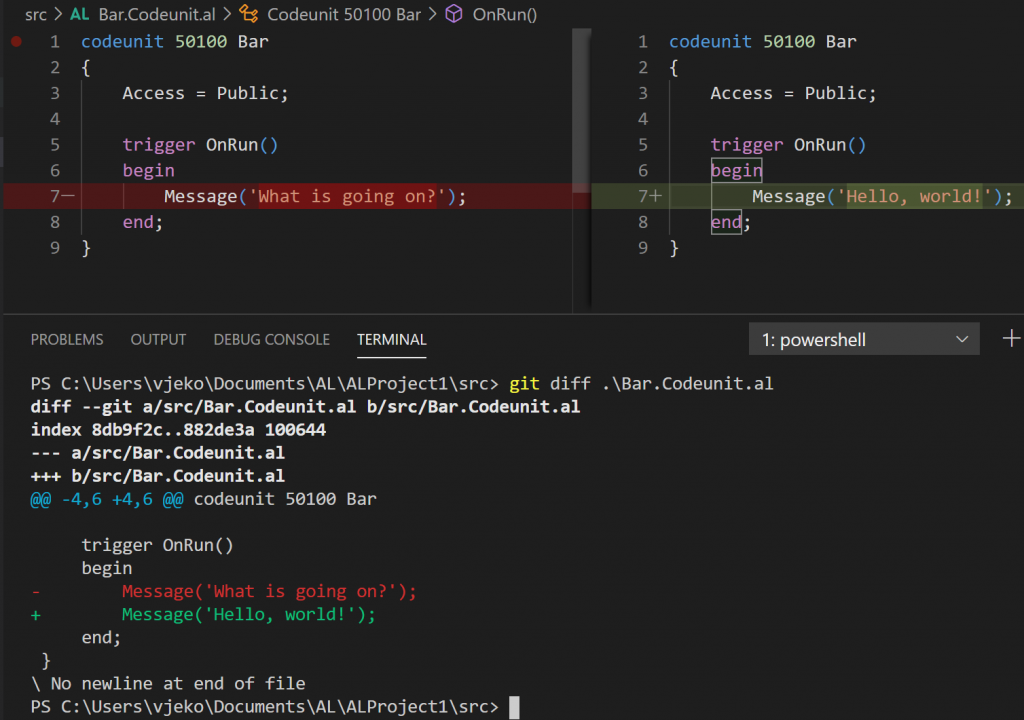
Representing that operation as an actual “change” instead of “add” + “delete” pair is what additional git tools do. But the fact that you see a change as “change” on screen does not alter the fact that git sees and treats this as “add” + “delete”.
This is the at the bottom of everything.
And this applies not only to lines of code – it applies to entire files. When you rename a file, git sees it as “delete” of the file with the original name, and “add” of a new file with a new name.
But if this is true, then why did we see the rename as a single file marked as R in the staged git view? And why does Git Lens show this history:
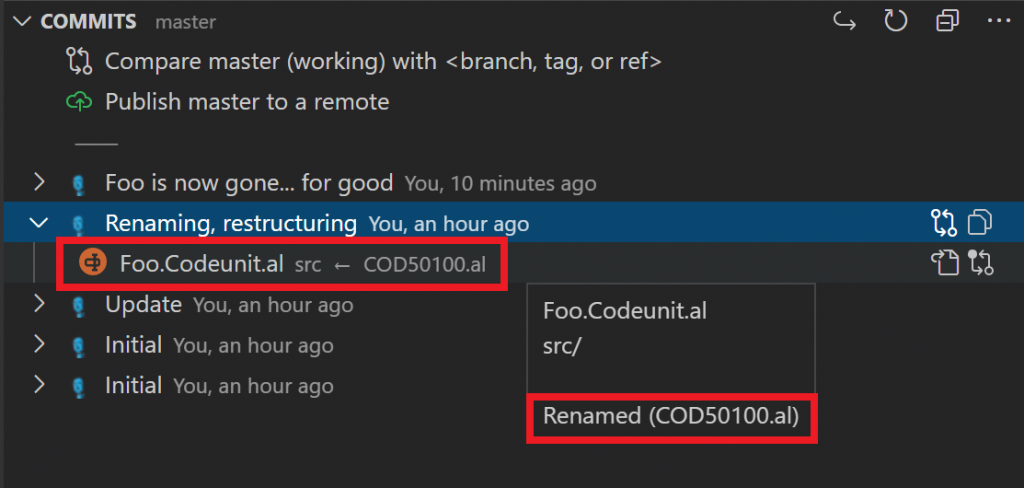
Looking in Azure DevOps will also show the file as renamed. So git must be tracking this as a rename. Right?
Wrong.
Git doesn’t track your rename. It, well, guesses it.
Heuristics to the rescue
When trying to figure out whether there are any renames, git does some heuristics. To do this, in each commit, git looks at two lists of files: “deleted” and “added”. This is where it starts.
From git perspective, file is not identified by file name only, but by file content. Whenever a file is added in git, git will calculate the hash of entire file contents. Two files with exactly the same content will have exactly the same hash. Their names won’t match, but their hashes will be equal.
So how does git figure out if a file was renamed?
First, for each file in “added” list, git will check if there is a file with exactly the same hash in the “deleted” list. If there is a file in both lists with the same hash, git immediately sees this as a match, and will treat this as a rename. So, even though git sees Foo.al as deleted and Bar.al as added, if both of them have the same hash, git shows this as a rename and is able to follow through the history.
This is also blazing fast, because it only needs do compare two very short strings, and even if you have thousands of renames (like, you rename an entire subtree, say from .\src to .\application\src with 3.600 files in there) git will match all deletions to all additions in a matter of milliseconds.
Second, after this first step of heuristics are done and actual rename pairs are detected, if there are still files left in both “deleted” and “added” lists git will actually look into file contents to figure out if some of those file contents were similar.
To do so, git will run <a href="https://git-scm.com/docs/git-diff">git diff</a> internally. Remember my example above where I not only renamed Foo.al into Bar.al, but also changed a few lines of code in that file. Git can still detect this as a move as long as git diff sees that more than 50% of the file content is the same. If there is more than 50% match, git will determine that Foo.al was renamed to Bar.al even though a few lines of code have changed inside. If git cannot find a file with at least 50% match, it will not see that as a rename, but as a deletion and addition.
You bet, this operation is far, far slower than hash comparison, especially if files are large.
And here’s a catch! When you both do a bunch of renames and a bunch of code changes, hashes will change for a lot of those renamed files, so git will have to run git diff for all files where there is no hash match. If there is only one added file, and one deleted file, git only needs to run git diff once. If there are five hundred files, there is a theoretical maximum of 124.750 git diff operations to run (the actual number may be smaller, because each successfully detected rename reduces the amount of remaining renames to be matched, but still – it’s a metric crapload of git diffs to run!)
When you rename an entire subtree, like moving .\src into .\application\src, while changing content of those files, and your subtree contains 3.600 files, that’s nearly 6,5 million git diffs that git would have to run to figure out if there were any actual renames there. Git won’t do it. There is a limit at which git will stop trying to figure that out, and will start treating the changes as simple deletions and additions. I tried to figure out what’s the limit here, and I couldn’t find any official info on that.
(If you suspect it has something to do with the ugly VS Code warning that says “The git repository at XXXX has too many active changes, only a subset of Git features will be enabled.” you are probably on a wrong train of thought. This is VS Code complaining, not git, so the actual cutoff point may be different.)
There is no such thing as a rename
Before I cut to the morale of the story, I want to reiterate a point: git does not, at any point, store the fact that a file (Foo.al) was renamed (into Bar.al). Inside its internal storage, the only thing git ever sees is that Foo.al was deleted, and Bar.al was added, and that’s it. Various git tools (like Git Lens, or Azure DevOps when looking at individual commits) may make you believe that rename information is stored, but it actually is not. Rather, every time you look at contents of a commit, all of the heuristics I explained above are done again.
This is why, when looking at a history of a file inside DevOps, or locally using GitLens for example, the history stops at the rename point. The last history of a renamed file you can see is when it was added to the repo (as the “add” part of the rename operation pair). If DevOps figures out, again using the same heuristics, that a file might have been renamed, it will offer you the “Show rename history” option. But all this feature does is guesswork, really. There is no hard history of renames.
I have some CLI (again) to prove it. Let’s check that previous commit to see if git sees it as a rename or as deletion plus addition:
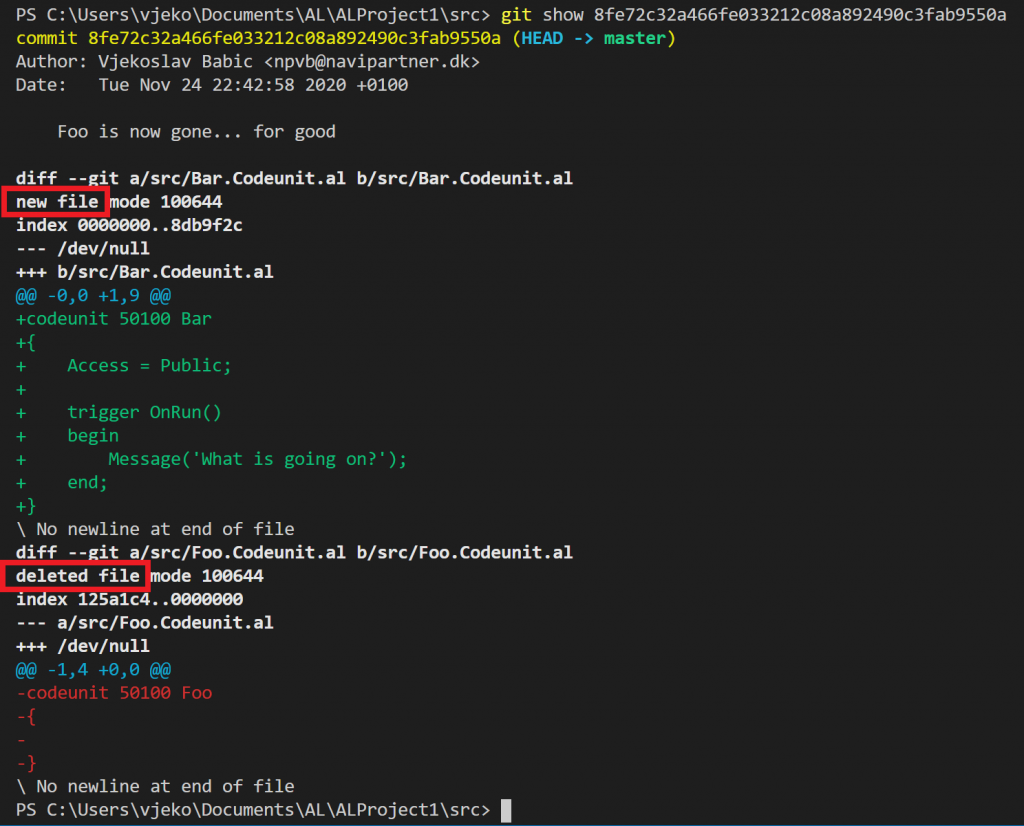
(Take a note of “new file” and “deleted file” that I marked in the screenshot)
But if I instruct my git show command to be less strict on differences and not go for 50% of changes, but to be happy if – say – 2% of the content is the same, we get this:
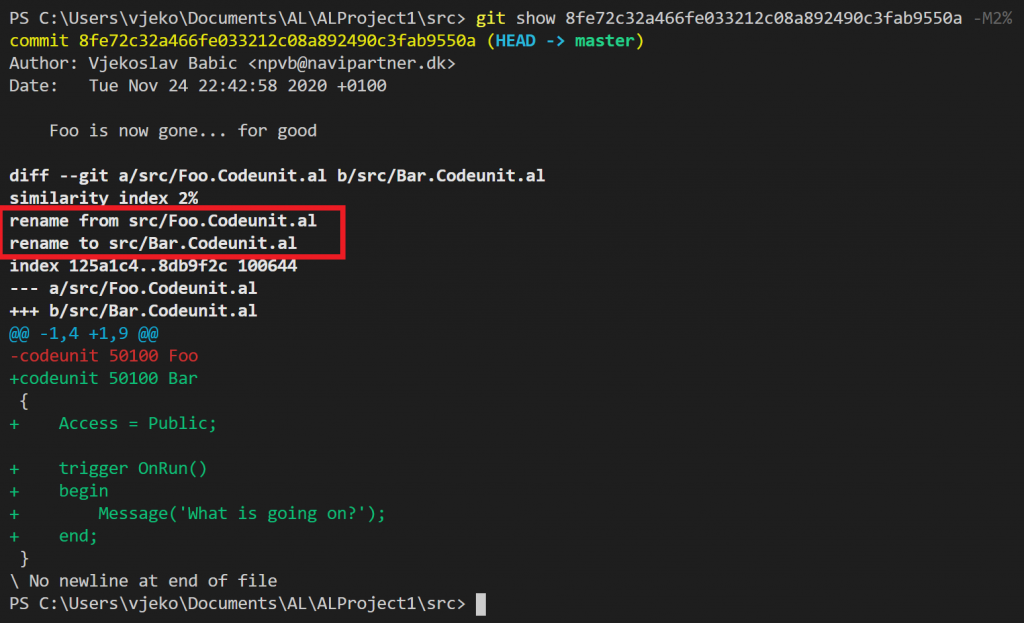
And now it’s a rename, what do you know. Except that it is not. It’s just that you asked git to take some latitude while guessing what might have been renamed.
Now, you may think you can outsmart all of this by using <a href="https://git-scm.com/docs/git-mv">git mv</a> (mv for move, and again, move = rename). If you think git mv will do an actual move (or rename), it won’t. What git mv is is nothing but a pair of <a href="https://git-scm.com/docs/git-rm">git rm</a> (for delete) and <a href="https://git-scm.com/docs/git-add">git add</a> (for add), it’s simply a shortcut. It’s not git mv that marks a file as renamed, it’s still the same git heuristics that will do it.
So, if you want to move 3.600 files and make sure git knows it’s an actual move, rather than just a bunch of deletions and additions, running git mv for all of those 3.600 files will be an exercise in futility. The results will be exactly the same as simply moving the file using the file system or VS Code or whatever other way, then stage and commit those changes. If you just do 3.600 moves, git will be fast at detecting that this has been in fact 3.600 renames, rather than 3.600 deletions followed by 3.600 additions. That’s because there were no changes in hashes for those 3.600 files, and git is extremely fast at figuring that part out.
Now, to the morale of the story.
Never ever move and change at the same time
Don’t do move/rename at the same time you do content change! It’s that simple.
When you want to restructure the repo, restructure it as one pull request. When you want to change content, change the content as a separate pull request. If you want to both restructure the repo and change the contents of some files for good measure, then you are bound for disaster! Depending on how many changes there are, git may see some of them as renames, but may end up actually not being able to figure this out for you when you need it.
This is the right workflow for changing structure of your repo:
- Create a new branch
- Do the renames/moves you intend to do without changing any of the file contents
- (Stage and) Commit the changes
- Push the changes and create a pull request
If you want to change the file content, this is the right workflow:
- Create a new branch
- Change the content of files you want to change without changing any of file names or paths
- (Stage and) Commit the changes
- Push the changes and create a pull request
This is the only way for you to be able to always follow the file change history through renames.
Thanks for sticking with me this far 😊 I hope you find this helpful, and that this helps you not fall into some git booby traps.


Pingback: Understanding renaming/moving files with git - Vjeko.com - Dynamics 365 Business Central/NAV User Group - Dynamics User Group
Vjeko, good post, like your sessions at Directions BTW.
To clarify (for me), in AL it is good practice to have the filename similar to the filename:
An al object that starts with: codeunit 50100 “Hello Foo”, will have a filename: HelloFoo.Codeunit.al.
So, when changing the filename, you also change the content of the al file. Don’t you?
Thanks!
https://docs.microsoft.com/en-us/dynamics365/business-central/dev-itpro/compliance/apptest-bestpracticesforalcode
Yes. You want to keep filename and object name in sync (as much as 30 characters limit allows you to).
Pingback: Understanding renaming/moving files with git | Pardaan.com