
If you have ever worked with Microsoft’s Team Foundation version control tools, it wasn’t easy to switch to Git. That’s not because Git was complicated – no, nothing like that at all! It was simply because you had to forget almost everything you thought you knew about version control, and then learn it anew.
There are many fundamental differences between Git and TFVC, and one of the more obvious ones to any newcomer to Git is this:
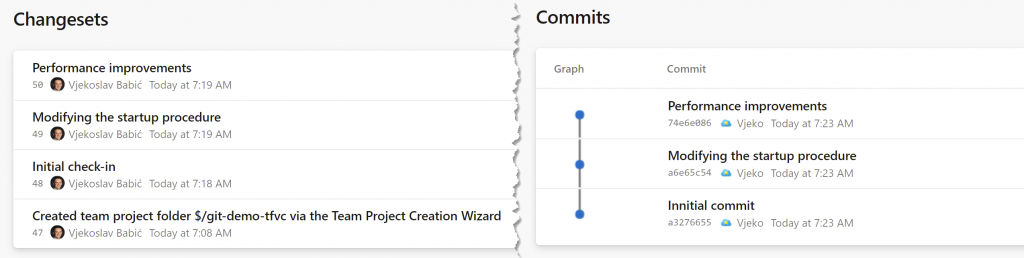
No, it’s not about the caption here. Indeed, TFVC calls individual snapshots of changes “changesets” and Git calls them “commits”, but that’s just terminology – the term in itself is not a fundamental difference. I am after something else here.
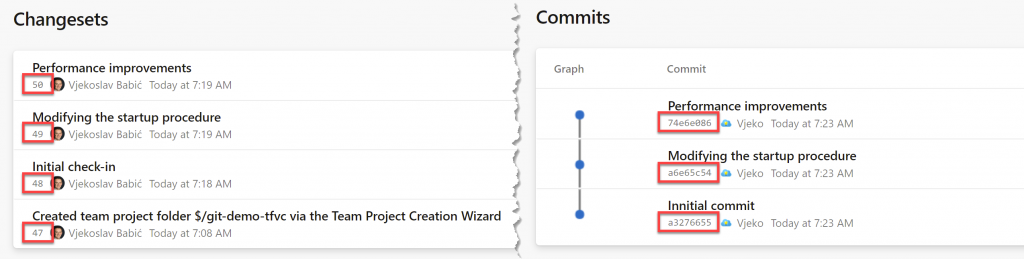
This is the fundamental difference I am talking about. On the left we have consecutive numbers, on the right we have some hexadecimal mumbo-jumbo that could be some unique identifier à la GUID for all you care, so what’s the big deal?
The big deal is that TFVC indeed assigns a consecutive numbers to the changesets it tracks, but for TFVC those numbers have absolutely no meaning. And that’s all I will say about TFVC, in this post, and most likely in my entire blog.
On another hand, for Git, those seemingly random hexadecimal commit IDs are neither random, nor meaningless. For Git, that number has a very important meaning, and that’s why it’s a good thing to know exactly what they are, how they work, and how Git uses those numbers.
Secure Hash Algorithm 1
Secure Hash Algorithm, or SHA-1, is a cryptographic hash function which takes an input and produces a 160-bit hash value known as a message digest – typically rendered as a hexadecimal number 40 digits long. It was first introduced in 1993, and it’s definitely not among the strongest of the hash algorithms, but for what Git needs it, it’s definitely good enough.
So what is it that Git uses SHA-1 for?
You could have guessed it already. Those commit IDs I showed you a minute ago – that’s right. They are hashes of the commit objects. As you can see, they are neither random, nor meaningless. Git uses these hashes to identify objects. Since one of the first requirements of all hash functions is that no two inputs should produce the same output, any given hash could be used to identify its original input, for all practical purposes.
SHA-1 does not identify just commits
Cool, so it’s commits that Git uses SHA-1 to identify, right? Well, no. It uses SHA-1 to identify all objects it keeps track of. Commits are just one type of objects. Strictly speaking, Git tracks three types of objects: commits, trees, and blobs. All of these objects are hashed, and Git uses SHA-1 to identify all of them.
However, typical users only ever see SHA-1 in the context of commits. You may have used Git for a decade, and you may have never ever seen a SHA-1 of a blob. Whatever blob is, in this Git’s eyes, anyway.
In won’t digress into explaining blobs or trees in this post. You may want to check out my last video about Git storage if you want to learn a little bit more about them: https://www.youtube.com/watch?v=YShTNKAUzrM
How does Git use SHA-1?
In simplest of terms, Git uses SHA-1 to identify an object. Any object. Before it stores anything into its internal storage, it will do two things. First, it will calculate the SHA-1 of the “thing” being stored. Then, it will check if that SHA-1 already exists in its internal storage. If it does, then it means that this object is already hashed and stored, and no need to store it again.
That’s what makes it possible for Git to stay lightweight. You can have a thousand files in your repository, and you only change one, and then you commit that change, even though Git stores the entire snapshot of your entire repository with that commit, since only one file changed, it means that only one new blob object had to be hashed, and all other objects remained there, since their hash didn’t change. Smooth.
Also, when you push or fetch objects, Git first checks their hashes. If there is a commit with a specific hash on the remote, and there is a commit with exactly the same hash in the local repo, then Git won’t fetch that object – it’s the same object. The same is true with pushing – Git will only push those objects whose SHA-1 values are unknown to the remote.
Pretty clever.
Are they really SHA-1, I mean…
But how can they be SHA-1, they are apparently only 8 digits long, and I’ve just said SHA-1 is 40 digits long? Actually, they are not 8 digits long in Git. Those 8 digits, that’s only what most Git tools will show you on screen. The actual commit ID is exactly 40 hexadecimal characters long.
It’s easy to check. Take a look:
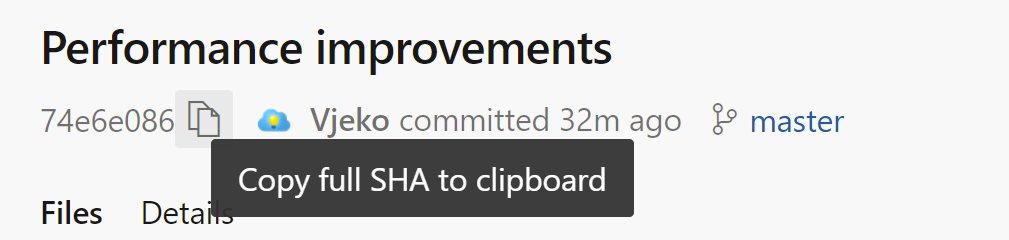
And this is what it gives me: 74e6e086b30f70f33ec3a97246001eb1817a4529.
Ok, ok, let’s take a step back. For most of the time, users won’t be aware of those whole 40 digit numbers. They will mostly see the first 8 digits. But they will mostly also do operations on those 8 digit numbers. Like, for example, if I were a geek that I am, I could easily do this in Git:
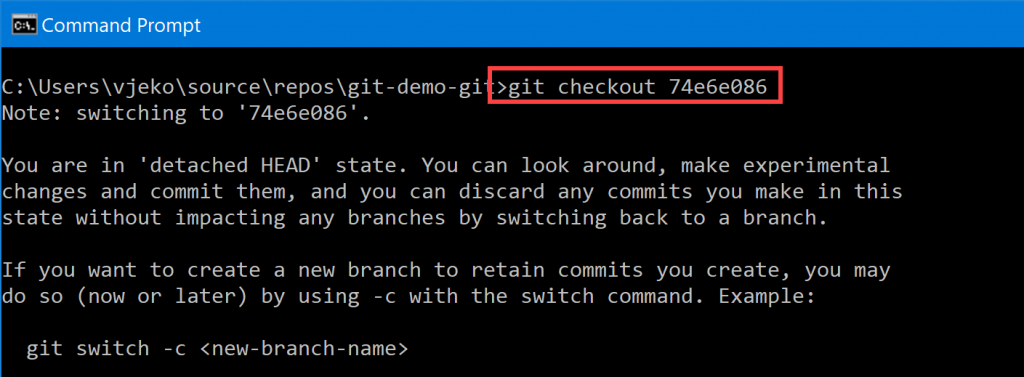
Ignore my “detached HEAD” state. Sounds far scarier than it is. Don’t lose your head over it. What matters here is that I have used the 8-digit commit ID instead of full SHA-1 to perform this operation. And it does not work just for detaching heads. Any Git operation that takes SHA-1 as input will let you do this.
So, if SHA-1 is 40 digits, and Git tracks commits by their SHA-1, why does it allow me to use only the first 8 digits to do whatever it is I wanted to do here? It’s because Git cares about being simple. As long as you only have one object in your repository with its SHA-1 starting with those 8 digits you used, Git will keep things simple for you, and will be smart enough to know that that single object must be the one you are looking for.
As a matter of fact, you don’t have to use even all of those 8 digits. Git will let you do this with as few as 4 digits. Take a look:
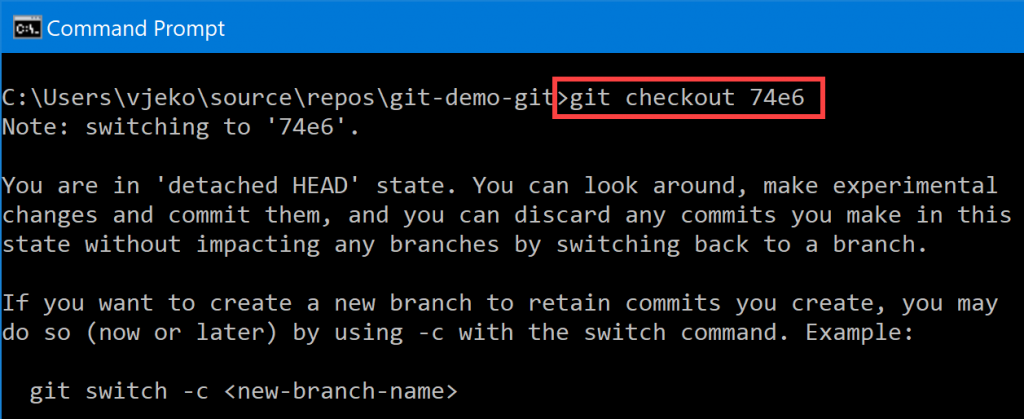
Here we go again. Me, detaching heads, with an ID only half as long as before.
But won’t this soon get you into trouble? I mean, obviously first four digits, or first 8 digits for that matter, they will soon start colliding, won’t they?
Big numbers
If you only ever use 4 digits, probably yes – at some point, but not that early into your project – you’ll start getting collisions. Let’s do some basic math.
4 hexadecimal digits, where each digit has 16 possible values, means 16^4. That’s 65,536 possible values. So, in the luckiest case, you need 65,536 different objects in your repository before you are guaranteed to get a collision, on the first 4 digits, that is. That means that at that many objects, you are guaranteed to not be able to uniquely identify any new object by only its 4 first digits. You don’t need that many objects, though. In practice, as soon as you reach half of that – 32,768 objects – you will be more likely to get a collision with every new object than not.
But think of it. 32,768 objects – that’s quite a big number. In the time of terabytes and gigahertz, that may sound small. But it isn’t. Many repositories never reach this high a number of objects. To verify this claim, I have done some research.
I googled this: “biggest open source project on github”. And this is what I got.
Ok, so I cloned freeCodeCamp and did git gc on it. Here we go:

So, that’s 288,577 objects. That’s what a project with 4,244 contributors and 27,417 commits, that has ran for nearly 8 years.
Just to put things into Business Central and AL perspective, I’ve cloned the ALAppExtensions project, it has 633 commits and 45 contributors. That one looks more like repos we’ll see in our companies. Guess what?
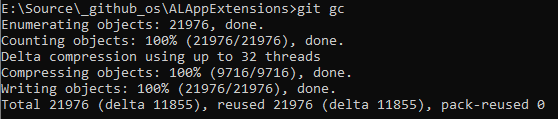
That’s 21,976 objects, after 633 commits from 45 contributors after just a bit over three years. Still, a lot room to go before we even reach a point where it will only be more likely to not be able to use 4-digit commit IDs on that repo.
If you look at 8 digits, that’s an entirely different ballpark. That’s 16^8, or in numbers that are only seemingly easier to grasp, it’s 4,29 billion different values. The actual biggest repo I could find (that’s VS Code, with 1,407 contributors and 81,078 commits over more than six years) has “only” 1,081,621 objects. It’d need to grow 3,970 times to reach a point where 8-digit IDs would start getting in the way.
But can hashes actually collide in Git?
A fair question. And an honest answer is: yes, theoretically.
I mean, it doesn’t take a rocket scientist to tell you that if you produce a digest value of any length from original values longer than that length, eventually you’ll get a duplicate. In SHA-1, it’s 40 digits, so if you produce a 40-digit digest (or hash) out of strings longer than 40 digits, you’ll get a duplicate. And most source code files I know are longer than 40 hexadecimal digits.
So… hashes must collide, eventually.
I mean, if we surely get a collision on the first 4 digits after 65,536 different hashes are calculated, and we surely get a collision on the first 8 digits after “just” around 4,29 billion different hashes are calculated, there must be some statistical chance that a collision will happen on the entire SHA-1 value, right?
I mean, maybe not in *your* repository. Maybe in all repositories in the entire world, there are two different source code files that have resulted in the same SHA-1 value, could that be possible?
Again, yes, theoretically. But practice is far, far, far, far from that. Did I say far? Oh, I did. So, how far?
Even bigger numbers
Remember. We’ve only taken a look at the first 8 digits. There’s 32 more digits to go. In its full capacity, SHA-1 can produce 16^40 different values, and in decimal notation it would take a lot of space to write. While 1,46×10^48 (that’s what 16^40 is in decimal) may not seem like an awfully big number, it actually is. It’s so ridiculously big that it’s even difficult to begin to imagine it. Our brains are not tuned to handle numbers that large.
Let’s do a mental experiment.
Imagine you have a computer that calculates one million SHA-1 values per second. You don’t have such a computer (yet), but for the sake of argument let’s imagine you do. Now, stand at an arbitrary point at the equator, and start that computer. Cool, so your computer now churns out a million SHA-1 values per second, and you stand at the equator, and you keep standing for… one billion years. Then, you take one step. Then keep the computer running until another billion year passes, and then you take another step. Then you keep taking a step every billion years until you walk around the entire equator and get to your starting point.
We are not done yet. Oh, far from that. Now take a teaspoon of water out of an ocean, walk over to the Grand Canyon, and pour that teaspoon of water into it. Cool, now walk back to your starting point, and keep repeating. One billion years you take a step. One full circle around the Earth you take a teaspoon of water and pour into the Grand Canyon.
By the time Grand Canyon is full, you are about done. Only then you will have exhausted all possible SHA-1 values.
That number is so large that with all of Git repositories around the Earth and all SHA-1 values ever generated in all of them, you haven’t even begin to remotely considering of getting ready to sometime in the foreseeable future start thinking of scratching the surface of it. If you hashed not every single source code file ever written, but actually every single line of code ever written, and you want to see how far you have filled the Grand Canyone, well… You haven’t put a single teaspoon in it yet. You’ve actually not even made a single full circle around the globe. As a matter of fact… you haven’t even taken a single step. At one million hashes per second, and one step every billion years, you would still have to wait for 980 million years before you could take your first step.
That’s where we currently stand in terms of all of Git repos of the world getting close to a SHA-1 collision.
But… SHA-1 was shattered
True.
So, in 2017 a team of scientists, mathematicians, and engineers at the Netherlands Organisation for Scientific Research and Google, have announced that they have brute-forced a SHA-1 collision. In other words, they’ve managed to find two completely different inputs that resulted in exactly the same SHA-1 value.
Check this out:

That’s from their website. There are two different PDF documents, both producing the same SHA-1 value.
While this is scary from the cryptography angle, it’s absolutely irrelevant in terms of Git.
Let’s put their effort in perspective. First, they were a team of scientists and mathematicians, fully armed with the deep inside understanding of how SHA-1 works. They knew exactly how to attack it. Since they understood how the algorithm works, they we able to devise an algorithm that makes it far more likely to produce a collision than hitting it with random values. That’s the first thing. The second thing is that armed with all that knowledge and understanding of the inner workings of SHA-1, they needed a supercomputer, and it took them nearly 10 quintillion brute-force attempts to break it.
And that was to produce a single collision.
And that was outside of Git context.
Ok, ok, wait a second. What does Git context have to do with SHA-1? Isn’t SHA-1 just SHA-1, if you have the same input, then no matter who calculates SHA-1, everybody will produce the same value.
True, but… not that simple.
Let’s first check how Git feels about those two shattered PDF documents. Let’s download them:
Once you download them, you can check their SHA-1 online at https://emn178.github.io/online-tools/sha1_checksum.html
You’ll get 38762cf7f55934b34d179ae6a4c80cadccbb7f0a for both of them.
Scaaaary 😁
But now, let’s have Git hash those objects for us:
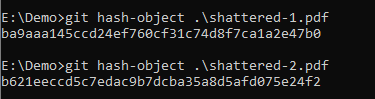
Uhmmmmmm… Er….. What?
What makes Git have a different opinion on what SHA-1 of these two files should be, than that website I used? Does this mean that Git doesn’t actually use SHA-1, but something else?
Git doesn’t hash the raw contents
First, to reassure you, Git does use the same SHA-1 algorithm as the rest of the world. SHA-1 is SHA-1, full stop. Git uses SHA-1 and doesn’t have a different opinion on what it should be.
Since different SHA-1 can only mean one thing – different input – then if Git produces a different hash of the same input document than another tool produces, then it can only mean that Git didn’t actually handle that document in its raw format.
And this is exactly what happens.
Git doesn’t hash the original, raw bytes of any input it receives. Before Git produces the hash, it first does two things:
- It compresses the input. I mean, it only makes sense, doesn’t it? Text files – and that’s what computer source code is – is among the most wasteful kinds of files in terms of space consumption. You can compress all text files down to 25% of their original size, on average. So Git does it.
- It attaches a small header. Yes, after it compresses the input, Git adds a few header bits indicating the type of object that’s about to be hashed (and subsequently stored). Git must know whether it’s storing a blob, a tree, or a commit, and it doesn’t have some central index telling it which hashed object corresponds to which file, and what it is. No. Git only has its object folder that’s organized by first two characters of SHA-1, and everything else is stored right in the files.
And this is why you will get different SHA-1 values from Git for those two “shattered” PDF documents, than you will get from plain SHA-1 tools. Git compresses them, and then adds a short header at their beginning. And only then it hashes them.
So, while SHA-1 has indeed been shattered, and while it does have serious consequences for any future cryptographic use of it, it has little relevance for Git.
Git hasn’t (yet) been shattered. The big difference between the Shattered.io experiment, and Git, is that the folks working on that experiment knew exactly how to attack it and they weren’t really throwing random values at it. The values were carefully calculated, then checked. With Git, even though there is nothing random (presumably) in source code, from SHA-1 perspective, source code files are truly random input. To try to force any two different – and meaningful! – source code files and have them produce the same SHA-1 after compression and header, would be statistically unlikely.
How unlikely?
Well… let’s try this. Take the Moon. Then copy&paste it until you have ten of them. Then put a blindfold on your head. Then pick a random atom from those ten Moons. Then pick a random atom from those same ten Moons again. The chances you’ll get two source code files colliding on their SHA-1 is about the same as you picking the same random atom from ten Moons twice in a row.
It won’t happen.
But what if…
What if it actually happened? I mean, yes, it’s unbelievably ridiculously unlikely it would ever happen, but strange things happen. What if, by a sheer case of bad luck, you got two different source code files in your repository and they produced the same SHA-1 value?
Will your Git repository explode in your face, just like all the computers exploded in all our faces on midnight of January 1st, 2000?
Well – no, it won’t. Nothing will explode.
While it’s difficult to say exactly what it would look like, because it’s impossible to reproduce that situation, we can make some reasonable educated guesses here.
Let’s call them File A, and File B. File A was committed first, and then File B gives exactly the same SHA-1. First, when you try to commit File B, Git would determine that this file already exists. It doesn’t, but since Git only ever uses SHA-1 to check if something exists, so it would think that File B is exactly the same as File A, and it wouldn’t store File B in its object storage. That’s it. Your repository, on your machine (the machine where the collision originated) would continue working just fine, you would still see File B as it was at the time of committing… until you switch branches. If you switch to a branch that doesn’t have File B, switching back to a branch that does would suddenly put a copy of File A in its place.
Most likely this will break your build, and you’ll figure out something is wrong.
Git can even help you make your way out of it. You can script git bisect to help identify the commit that caused the problem. Once you do, you can fix the problem by simply changing anything in File B. Adding a comment line, or a line break at the end, or something like that, gets you out of the mess.
And that’s it. The world wouldn’t end. Just like it didn’t end on 01/01/2020.
That’s all, for now
Well, that’s it. That’s all I had to say about SHA-1 and how Git uses (and doesn’t use) it. The more you learn about Git internals, the more amazed you’ll become with all those little, but smart decisions made on practically every step of its internal design. Git is one incredibly smart piece of software, while at the same time bearing this humble name “Git”.
If you want to learn more about how Git works inside, especially from practical perspective that can help you be more productive with Git in your daily development work, join me in my Leveraging Git webinar on May 10-12, at 16:00 (GMT+2). I’ll make sure it’s worth its salt.



{kind=link}
That’s greatly written. I love the examples you used to explain everything. Thanks for an entertaining post about Git 😊
Thanks, glad you liked it! 🙂
Great Reading, now git internals seem not so scary, even with all these detached heads 😀
That explanation makes so much sense.beautifully explained.