AL Object ID Ninja Scheduled Maintenance Announcement: October 9 at 19:00 CET
For all of you using AL Object ID Ninja, please read this post. There will be scheduled maintenance of AL Object ID Ninja back end on October 9, 2021, at 19:00 CET (UTC +2). The expected downtime is 30 minutes. During the maintenance, you will not be able to use AL Object ID Ninja to assign object IDs.
Behavior during the maintenance
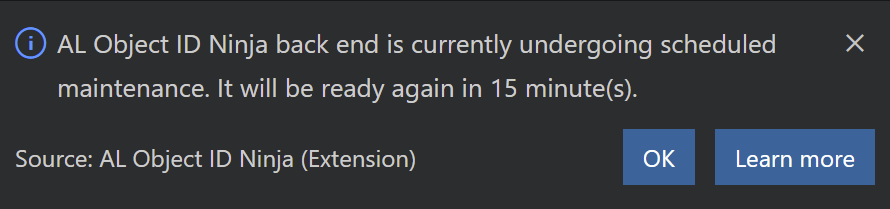
During the maintenance, the back end will send the 503 Service Unavailable response to all requests. When AL Object ID Ninja receives this status, it will show a message like this:
What is this maintenance about?
In my previous post, I explained the reasons for the maintenance that is going to happen this week. After weighing in and out several approaches, I have come up with a plan slightly different than what I announced in the previous post. So, during this maintenance, the following is going to happen:
- All existing app information will be moved from a Standard-tier Block Blob container to a Premium-tier Block Blob container. This will provide a slightly better performance, and will reduce the costs by roughly 47%. Standard-tier costs less for volume of stored data, but more per transaction, and since Ninja is using low storage volume with high transaction count, the cost reduction will be substantial.
- All blobs belonging to an individual app will be consolidated into a single app blob. In “v1” app information is spread around multiple individual blobs which allows slightly faster performance and lower access concurrency. However, benchmarking has shown that there is no substantial performance benefit to existing approach as compared to single-blob-per-app approach. Furthermore, since the back end already correctly handles concurrent access and since chances of actual concurrent write are microscopical, not much is gained by spreading app data across multiple blobs. The overall benefit of having a single blob is substantial, as there will be far less blob read operations as compared to the current situation.
- After the migration is completed, a new version of back end will be deployed that will return the 410 Gone response to all “v1” requests. This version will have “v2” endpoints available.
- When the migration starts, a new version of AL Object ID Ninja (2.0.0) will be deployed that will access new “v2” endpoints.
What do you need to do?
After the maintenance completes, you should update AL Object ID Ninja extension as soon as possible. For most of you, this will happen automatically. To make sure everything is ready, verify that AL Object ID Ninja is updated to 1.2.8 in your instance of Visual Studio Code before you first start working after the maintenance.
IMPORTANT (if you have your own back end)
Some of you are using your own back end. I will push the new version of the back end to GitHub latest on Thursday evening. Please keep an eye on the repository. When you see a commit about back end “v2”, pull the changes and deploy them at any point after the scheduled maintenance starts, but before your developers start using AL Object ID Ninja (probably on Monday morning).