
One of good practices of writing C/AL Code for Microsoft Dynamics NAV since the dawn of civilization was annotating (commenting) code changes. If you are not sure what I mean by that, this is what I am talking about:
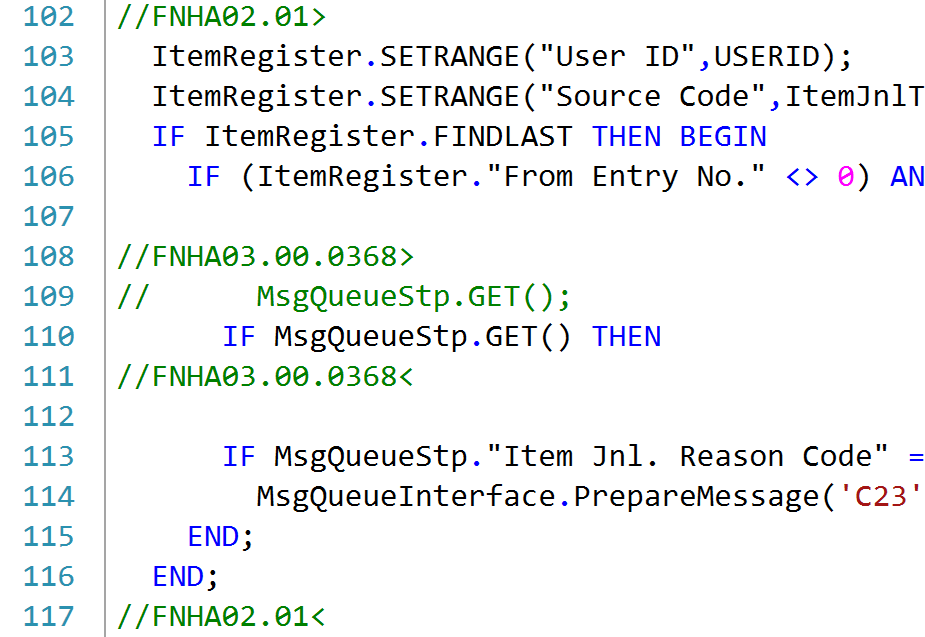
While standards varied about > vs +, or < vs -, or what the annotations should include, there was absolute consensus that annotating changes is an absolute must.
And it was a must. It was such an important rule that everyone followed it without questions asked. In my career, I’ve seen one or two situations of somebody changing or deleting a line of code without leaving any comment, and I’ve seen quite a lot of code, believe you me. It was that important.
It was that important in fact that it was one of the first things developers learned when they signed up for the job, and it was one of the rules they all followed from their first day.
Rules and habits
But as it often happens with rules, this rule slowly turned into a habit. Rules get introduced because they are needed. They all have a why part to them. Then they spread around and gain wide adoption because they are good, and they work. But then, at some point, they turn into habits, because people keep applying them even after their why part has been long forgotten.
Sure, nobody really forgot the why of this particular rule. Every developer worth their salt will tell you right off the bat that these annotations were necessary because that way we can track code changes from version to version, and it pays off when doing upgrades and merges.
But no single why ever comes alone. That’s what Sakichi Toyoda figured out a hundred years ago when he developed his Five Whys technique of getting to the root cause of anything. One why is shallow, it tells you an immediate cause. But five whys will get you to the root cause of any problem, he postulated.
In our case, we don’t really need five whys to get to the root reason of why we really needed code modification annotations. And the answer is as astoundingly simple, as it seems to be much forgotten: because we had no other way of tracking code.
Really, why?
You know, our development tools of old, the rest-in-peace C/SIDE and C/AL, were developed in another millennium, long, long before any source control management was invented.
The root reason why we annotated our code was because NAV had no built-in way, and no easy way of tracking code changes. The only way of being always able to track a code change together with the who, when, what, and why of that change was to put those annotations in there and keep them sacrosanct. Yes, there were tools, and there were attempts by many (even I did it, and it gained quite some traction back in the day and people apparently still download it – what the heck they use it for I have no clue…), but they were just that – attempts. The sad truth is – we never ever had anything close to a true source control management tool that just worked.
Enter git
Fast forward a quarter century, and there is a new kid on the block: git. Git can do all those things we dreamed about. And more. A lot, lot more. Git can track a code line from the beginning of time to the end of it, it can tell you who ever changed it, when, why. It allows you to compare, merge, automatically, manually, you name it. It comes with so many powerful options that it practically displaced all other source control tools out there (when did you last see someone use SVN, or Mercurial; heck – even TFS is practically unheard of these days).
And guess what? With git, all the reasons for code annotations are gone.
Still, a few days ago, while handling a pull request on a Business Central extension project, I was flabbergasted to find it full of code annotations. Every single smallest change was duly annotated, as in the heyday of Navision Attain. Needless to say, merging that pull request took some manual time to get the changes properly into the repo, because git couldn’t handle it itself and it kindly asked for my manual attention. Mind you, none of the changes were actual conflicts – all of them were extremely simple line modifications or block additions.
And then I decided to do two things. Three things, in fact. The first one was to write this blog post and share my firm opinion conviction about this practice. The second one was to create a git repo with a bunch of examples of what can happen if you keep this practice alive in the git world, as opposed to what it all looks like when done cleanly. And the third one was to ask around and see if this was an isolated case or something that people still just do.
Please, don’t
Yes, I am completely convinced that in the world of git, this practice is completely obsolete, unnecessary, wasteful, and even harmful.
Ask any C# developer, C++ developer, Ruby developer, Python developer – heck, just about any other kind of developer there is – what they think about this practice. The best response you will get is probably along the lines, of: “Huh, what again?”
You see, those guys, they never annotate their code changes. That’s because it’s unnecessary. Why would you do that? When you need to change a line of code, you change it. When you need to delete a line of code, you delete it. No big deal, no ceremony, no fanfare. Just change, and move on. When you commit that change, git will take care of everything. It will tell you who changed it and when, and with good git commit comment practice in place, it will tell you why, too.
And please, don’t give me that “but we are different, AL is different than C#, maybe they don’t need it, but we do” line of reasoning. It’s bollocks. Code is code. Git is git. Git doesn’t care about the language you use, and git can handle any language. And AL is not the most complex language out there, take my word for that if that’s not already as obvious as the nose on your face. No special treatment needed for AL.
Let’s try to delve into the original whys of our code annotation practice. We needed it so we could trace who changed something and when. Cool, git tells you all of these without you having to do anything at all. Git allows you to compare between commits, and see the results of those comparisons side by side. If you don’t feel comfortable with git diff (and why should you), then there are a bunch of tools like GitLens, that can automate this and similar tasks. You have git blame to tell you who and when changed what, and VS Code can give you a nice overview of that, right out of the box. No need for annotations.
But what about merge, you ask? Yes, what about it? Git merges things automatically. You change something in your branch, then you merge that to another branch. If your branch started off from the branch you want to merge into, then it’s a no-brainer, your changes just go there. Just like that. If somebody merged something else to the target branch in the meanwhile, and target is ahead of you now, or if you merge across branches, you still stand good chances of git never asking a thing. Git is amazingly good at handling conflicts. Unless the target branch was modified at exactly the same places in code, git will be able to merge it just fine. You can have five people change the same file in five different branches, and you can then merge all of those branches into the same target using octopus strategy, and git won’t complain unless different branches changed the same lines of code. If each branch changed a different place in code, merge will just work. The only situations when merge will fail is if one branch changes the same region of code that was changed or deleted by another branch after the source branch was branched off the target branch, and that’s it. And even when there is a conflict, git will clearly show you what the conflict consists of, and VS Code allows you to resolve most conflicts in a single click. No annotations needed.
But every time I said “no annotations needed”, it was an understatement. Your annotations are not merely not needed. They are actually harmful.
When you introduce annotations in your code, you are actually making it far more likely for conflicts to occur. When multiple people work with the same file and don’t annotate the code, then git will most often be able to merge those changes without a conflict. However, once you introduce annotations, you are increasing the potential conflict surface and merge conflicts will start occurring where there should be none. And it’s dangerous, because it will cause you downtime. You’ll have to manually handle all those situations that normally require no human attention, because git is designed to handle these situations for you.
//> Mess.v3 // // > Mess.v2 // // // > Mess.v1
The ugliest consequence of code annotations always was the fact that after two or three cycles of changes, your code becomes unreadable. Heavily annotated code maybe helps you gain insight into who, what, when, and why (all of which are already answered by git), but the answer is not straightforward, it’s actually messy and complicated. The following screenshot tells it all:

Can you really tell what’s going on in here? Compare it to this:

With a little bit of GitLens…
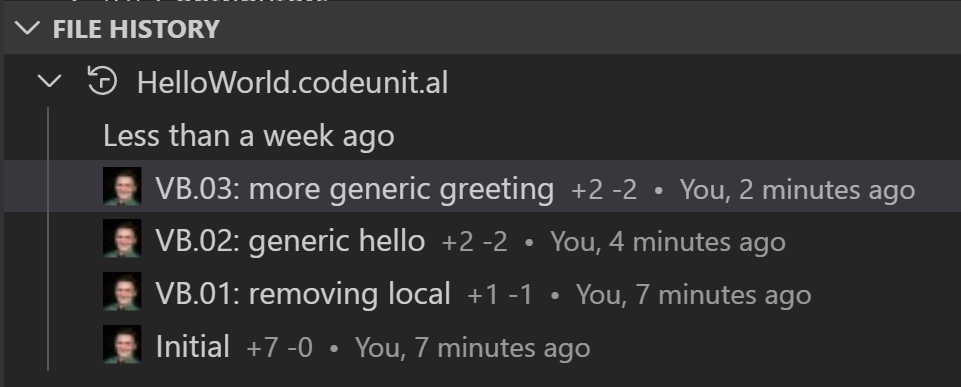
… and click-to-compare (still from GitLens)…

… everything is far, far, far more clear than any annotations can tell. Especially because that annotation mess above is only three layers of changes; I’ve seen six, seven, even more, and not once.
I wasn’t lazy – I actually built an entire repo with 18 branches in total, where I show in parallel what happens with an annotated “tree” (I don’t know if that’s a correct term for a hierarchy of branches) and what happens with a normal, non-annotated, natural git kind of “tree”. I also show there how conflicts occur with annotated branches, where non-annotated counterparts happily merge without a sound.
However, I want to explain that repo with the branches in there, and what’s being done in each step, and what’s going on when you merge, and that would make this post far too long, and would veer a bit too sharply towards level 400. So I’ll do it in a follow-up post.
Isolated case?
I was really curious about whether the case I experienced was isolated, or if there is this still a practice out there. I talked to a few people (but really actual people, not “a friend of a friend”) and apparently there are developers out there who still do this.
Five monkeys
This reminds me of the Five Monkeys story I blogged about eleven years ago, and it’s a typical example of when a practice becomes so common that everyone stops thinking about it, and then people come and go, and the practice survives everyone that remembers why, in the first place, it was even started. We often mock this kind of practices when we encounter them with our customers – so often their business processes are ages old, and make no sense at all in the present, but they are still doing it because that’s how things are done around there. Don’t fall victim of this yourself.
Be smart. Be efficient.
{kind=link}
First things first – thanks for this interesting reading. The new AL world looks great, almost ideal. No more comments, yay.
Yet me wonders if it is really all that great, and git features cover all the cases that the call “Don’t do it at all’ is really justifiable.
What if there are some more complicated changes to the code. What if there is more than one specific purpose of changing in your code? What if the code uses some something tricky technique, or is not really that obvious as change Setup.GET(); to IF Setup.GET() THEN…
What if there are more different tricky things in a different places in your file. Yeah, a programmer worth their salt my scratch his head and finally get the why, yet adding a short comment with the explanation would probably save some time spend on understanding why the changes are the way they are.. A git commit comment imho won’t work as good as a few lines of comments inserted in between the code lines.
A little digression here – I’d dare to say that even such a simple change like Setup.GET() into IF Setup.GET() THEN… could be potentially confusing or considered by others as a bug in code. Myself, for example, I’d personally prefer the Setup.GET() over IF Setup.GET().. I’d argue that if the execution got to a part of a given module the setup record for the module, if it is meant to be used, it must exist. The check for presence of a setup record should be done when the access to the module is enabled, and if the access is enabled and the code got to the place where it needs the setup record, then setup must exist and the program should rather complain about missing setup rather than silently ignoring the missing reocrd and skipping some lines of code..
Agree – who, when, what – adding comments/annotations answering those questions is no longer necessary in Git era, and it can negatively impact Git efficiency. Yet in my humble opinion the ‘why’ (and sometimes ‘how’) is still best explained in form of a few comment lines in between code lines.
Thanks for the comment, but I have a slight feeling that we may not be talking about the same thing. My blog post about code change annotations, not code comments in general. The code change annotation is when you have something like this:
Setup.Get();… and then you change it into this:
//SG.01> //Setup.Get(); if not Setup.Get() then begin // ... end; //SG.01<… instead of simply doing this:
if not Setup.Get() then begin // ... end;In the example above, the //SG.01> and //Setup.Get() are code change annotations, and this is what my blog is about.
Now, if you are talking about adding changing this:
Setup.Get();… into this:
// Must not use unconditional Setup.Get() // because of xyz if not Setup.Get() then begin // ... end;… then this is code commenting and it’s a completely different topic, and my blog post was not about that. Code commenting practice in general is a topic of its own, whether or not this is allowed, desirable, good, bad, needed, whatever – has nothing to do with this post. Many people have their own opinion about this kind of commenting, my own is pretty much aligned with that of Jeff Atwood (most of my opinions about programming are formed by reading his blog since my earliest programming days) and I don’t intend to ever post about code comments.
However, as far as code change annotations go, in any decent SCM scenario they are unjustified, any kind of them, in all circumstances, always, full stop.
Agree, commenting the code (answering ‘why’ and ‘how’ questions) and annotating the changes (who, when, what and where) are two different things, But let me be picky and point to the first sentence in your blog post when you sort off some merged the two together 🙂 Further example below sure adds some clarity, still, me being picky… 🙂
My first sentence is “One of good practices of writing C/AL Code for Microsoft Dynamics NAV since the dawn of civilization was annotating (commenting) code changes”. Where exactly do I mix the two? I am talking about “annotating code changes” – that’s the stage I set in the first sentence, and then I give example of annotating code changes, and then I spend the rest of the time talking about code changes annotations. At no point in my post did I talk about commenting. The word “commenting” in parentheses that follows after the word “annotating” merely indicates that for the purpose of the rest of the article “annotating code changes” is the same as “commenting code changes”.
Thank you for this blogpost! It is funny how awkward it felt to me to drop the code annotation habit when I started developing in AL. There are definitely still people who annotate like in good old C/SIDE days. I guess that is mostly due to a lack of information.
They just assume that the old way is still the right way. The next time I have a discussion about code annotations in AL I will simply point them to this blogpost – problem fixed 🙂
Thanks for the comment, I’m glad you find it useful! 🙂
Passing from C/AL to AL and get rid of annotations will make many developers happy.
However, the good habit, set annotations in C/AL, must be replaced with another good habit. A structured way to do commits, stages and commit staged. A commit must follow after each individual task/development – if a developer will just commit everything with mixed things then will be clumsy.
Git offer multiple tools for code structure and control. How do you see the best ways to do extensions for D365 BC ? Use multiple branches,work with stages etc..? As many developers are following you maybe you can write about it.
Pingback: ArcherPoint Dynamics NAV Developer Digest - vol 273 - Microsoft Dynamics NAV Community
“and people apparently still download it – what the heck they use it for I have no clue”
You do. As all other “MVPs” pushing the agenda of “C/AL and C/SIDE are dead”….
95% of NAV customers are pre-AL and pre-extensions based. And you know that. Instead you prefer to broadcast the agenda of “C/AL is dead”.
It may not be developed/enhanced anymore, but it is still the main dev environment on vast majority of NAV implementations and support based projects. BC volume is under 5% of active customers worldwide. The rest is old C/SIDE based NAV.
It’s ridiculous these basics have to be explained. Though you perfectly know it, hands down.
Same accent and intonation in blogs of every single glorified MVP.
Agenda? Come on, “C/AL and C/SIDE are dead” is not an agenda – it’s a fact. Maybe 95% of NAV customers are still on pre-AL, but I don’t care. Dinosaurs were 95% of animal kingdom, and then they went extinct. By the way – your numbers, that 95% you mention – that’s of course an actual, well-researched figure you got from surveying the market, talking to people, attending the conferences and talking to partners to see how much money they invest in AL as opposed to C/AL? Here’s for some actual, verifiable numbers: 95% percent of ERP market is not NAV – should I now blog about some other ERP technology perhaps? 97.5% of cars are not electric – should I buy a diesel car? 90% of energy is not from renewable sources – should we all throw all the solar panels away now? I don’t care if you want to stay with working with C/AL – that’s entirely your choice. I have a suggestion for you: why don’t you blog about C/AL and S/SIDE? Because 95% of NAV market apparently does not care about what 95% of bloggers are blogging about – correct me if I’m wrong, but but this is a huge opportunity for you right there.
Trust me, there is no agenda on my blog. There is no conspiracy. And by the way, the Earth is not flat, the vaccines work, mankind did land on the Moon, and there is no Santa Claus. Sorry for breaking the bad news to you.
“Trust me, there is no agenda on my blog”
Alas, there is… At least, that’s how the community sees it.
Marketing, marketing, marketing. You guys do what Microsoft is expecting to be done by glorified MVPs…
50%+ of customers worldwide will be on NAV/C/SIDE 10 years from now. AL/Extensions will still be a minority. Absolutely, undoubtedly.
The mantra of kinds “I have no clue why you need it”, “suck it up, move to AL”, “the message is clear – C/SIDE is dead”, “look at this beautiful web client”, “the product has never been so great than it is now” and other bla-bla-bla-bla-bla-blas is just a joke…..
It’s not a problem for me personally, as I just laugh reading this pathetic nonsense. However, what you personally and other MVPs, are doing by confusing customers and seeding panic is just terrible…
Don’t feed the trolls, they told me…
Can’t lose by calling an opponent a troll. Unbeaten tactic.
Especially, when there is nothing to reply.
All the best in 2020.
That’s because you are a troll. You came to my blog with unsubstantiated claims, accusing me of things that can’t be farther from the truth. I challenge you: find one article on my blog that’s marketing, where I am singing praises to things you say we “glorified MVPs” sing praises to. My blog is about how to use a product, about how to overcome technical challenges with it, how to solve problems people will stumble upon. I write about tips and tricks and lessons I’ve learned on my journey with the product I am passionate about. I share my technical solutions for free, my knowledge for free, my experience for free, my code for free. What do you have to show for?
Yes, I am an MVP, and I am proud that I am. I don’t see myself as “glorified”, though. I am not doing this for glory. And I am certainly not doing this because my opinion is for sale. It’s not. Again, I challenge you to find a single marketing post here, where I am singing praises. On the contrary, you’ll find quite a number of those where I am critical, sometimes very much so, about the product as well as about Microsoft. I don’t know how it looks from your angle, but I can assure you that Microsoft doesn’t give me my MVP so I can sing praises to them for free. They never asked me to write something they want me to write, nor they ever asked me to remove something from my blog that they didn’t like. My blog is my honest opinion, unspoiled, unsold, and totally not marketing. Apart from your summary accusations, and numbers you pull from you know where, what do you have to show for? That’s why I call you a troll, and that’s what you are.
And yes – absolutely – I am blogging about BC and AL because that’s where my interests are. I have blogged quite a lot about C/AL and C/SIDE back when they were actual and when I was interested in them.
Maybe you are right that 95% of customers and partners are still on C/AL or that in 10 years 50% of them will still be on C/AL – I still don’t care. They are not my target audience anymore. I care about new technologies, exploring new things, learning new things and sharing my learnings with those who may happen to care about those things. That’s what I’ve been doing – for free, unsolicited – for twelve and half years. What do you have to show for?
I thought so.
And that’s what makes you a troll.
Well.. It does look a little stinky..Not your blog in particular, but Microsoft’s actions and overall very, very enthusiastic reception by most, if not all MVPs..
If you look at it from a perspective : NAV (and now BC) is a massive ERP system. There is a steep learning curve for new partners and users. Systems of this size and complexity, require quite an efforts to get it running and train users. Time consuming and costly efforts, therefore you’d expect systems like this to be rather stable. Yet Microsoft got a diarrhoea with new versions. Even their initial promise of a new version every 2 years was a very fast pace, now we have new version every 6 months.
Questionb is – are these really a new versions? Does NAV 2018 differ from NAV 2017 that much to call it a new version? Or BC 13 from BC14? or BC14 and BC15? Do “new versions” are indeed an improvement?
Lets look first from customer point of view and ask if customers benefit from such a fast pace of releasing new versions? Personally I doubt it as it the new versions were mostly changes of the platform, not so much the application or functionality. Did the platform got better? In some aspects yes, but in another aspects it got worse. Much worse for existing “C/AL clients”, but not only for them. It became worse from performance perspective for new customers with bigger date sets – due to the way how the table extensions V2 are implemented. Worse with possibilities of precise adaptation to customer;s business environment. With C/AL gone BC15 is even now no longer truly customisable. Yes, you can download the base app and modify the source code – but all MVPs, including you, advice strongly against it. Should a bug happen in the MS code base let’s pray that it will be fixed in the next CU (and that nothing else will be broken…)
So why MS adopted such a crazy fast pace of new releases? They wanted new customers for sure. I don’t blame them for this – who wouldn’t. But it is all happening at additional cost created for existing customers. Every release means new license agreement, and taking older version out of sale and support. When you connect this with NAV to BC licensing mode change to named users and subscription based licensing you may wonder.. In the ‘old’ world if customers, or partners didn’t like what MS is doing they could ‘protest’ by not paying the yearly service fee. Once you have purchased the license you could stay with particular version for how long you wanted (or for how long new MS OS/patch release didn’t break it). With a new version every 6 month and named users and subscription licensing MS holds everyone over the barrel – pay or go. If you were “smart” enough to have your data in the cloud then, well, you won’t even keep this. If MS decide to bump prices another 25% like the last time, or 50%, or 100% – again – your alternative is to pay or to go. Go without access to your data.
Microsoft promised the bells and whistles, in 2018 they promised that C/AL will stay for at least 5 years, promised “no more upgrade with AL” and instead holds us to a ransom, err, sorry, subscription license, and a model not letting existing customers to carry out their business at the pace they want/like
Are all that MS business practices, and the direction NAV is going so nice and flawless that they deserve only praises? Were those limitations hard to predict a few years back, when the BC/AL ball was starting to roll? No, not really. Did any MVP protested against this direction, or even mentioned flaws and risks for partners and customers? I don’t remember any, well maybe except Mark Brummel who had the guts to tell Microsoft “no thank you for your MVP”
Even you have taught us tons about .NET in NAV, and posted lots of really helpful stuff, just to make a U-turn in 2018. To be honest it was a bit embarrassing to listen for most part of your 90 minutes Techdays2018 session wasted for explanations why .NET is now (quite suddenly) bad in NAV/BC.
So yes – you were sometimes critical about the product, its flaws as they were at times, but I don’t remember you, or other MVPs, being critical about general direction of NAV evolution. Don’t remember MVPs poining out risks – business and technical – even when the future version flaws were quite blatant. Did you even say “removing C/AL is wrong for majority of existing customers”? Quite the opposite we can read above : “They are not my target audience anymore.” You don’t care, and so doesn’t Microsoft, nor the other MVPs.
Don’t be surprised that some ‘old’ NAV people may feel betrayed and angry, and see/suspect some kind of agenda in your / other MVPs blogs.
I know – you don’t give a s..
Too many points for me to give you a deep meaningful response, but I’ll try bullet points:
Great post and an interesting debate. 🙂
Coming back to annotations, do you know a way to remove all of them from a repo? I’ve upgraded source code to AL and I have thousands of them. My best choice is to use regex, but I’m not sure whether it’s bulletproof or I’ll end up with deleted lines of code (since I have annotations at the end of lines of code as well).
Sorry, I don’t know of an easy way to remove all annotations at once. Regex could work as long as your annotations are consistent and always either consume the entire line or are at the end of the line. However, if they aren’t consistent, then I wouldn’t recommend using regex.