First things first. Yesterday evening, I’ve released AL Object ID Ninja v1.2.0 and there is really nothing new that you’d care about, functionally speaking. Check the changelog if you will, but trust me, you won’t be really blown away. But yes, unfortunately, it did merit a full minor version rather than just a patch number increase.
That’s it. If you only care about what’s new, then this is where you stop reading. But if you care to know what kind of a rocky ride I’ve had yesterday wrestling with Azure and fighting like mad to keep this service free, then read on.
I won this fight, by the way 😎
Wow, what a day! I have expected one minor release yesterday (v.1.1.0) but then my day turned out quite different than what I had expected when I sat at my keyboard yesterday at 6:30 AM.
AL Object ID Ninja has launched to quite some clout and more success than I expected. I don’t know for a fact how exactly Microsoft calculates trending positioning on the Visual Studio Code Marketplace landing page, but on Monday morning, Ninja was already in the Trending this week group, and by the end of the day it was in #1 Trending today. Yesterday morning, it was #1 in Trending this week and #2 in Trending this month and just by seeing this I was already high.
And then there was this cold shower. Azure Billing notification.
Money Makes the World Go Round
It’s one thing to run an open source project, but totally another ballpark running a free public API on Azure infrastructure. As you may know, there is no such thing as free when it comes to Azure, and for anything to be free for you, it must be not free for someone. And in this case, that someone is me.
When I started this project, I did some Azure calculations. I guesstimated the possible number of concurrent users (I put that number at maximum ~5000) and then knowing (better yet: thinking that I know!) what’s going on in my back end, I’ve reached the grand total of maximum ~€30 per month. Theoretical maximum I’ve decided to sponsor myself before I start looking for third parties to sponsor it was ~€100 per month. But – I was sure I’m not going to see those numbers. Based on what my Azure Billing notification presented to me yesterday, I would have depleted my entire budget for September on… next Monday!
Long story short – Monday alone had cost me €14.99:
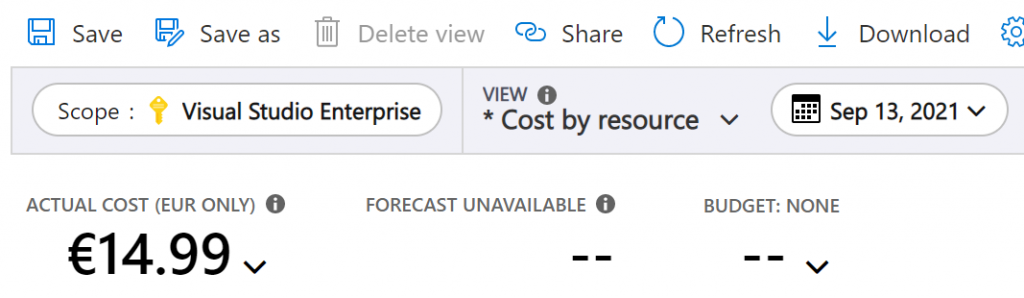
If you are ever running a free service based on Azure, I hope you don’t wake up to numbers like this.
I drilled down into details to see how in the earth is that possible, because I have estimated the numbers before starting this thing, and it made no sense. The drill-down report made even less sense!
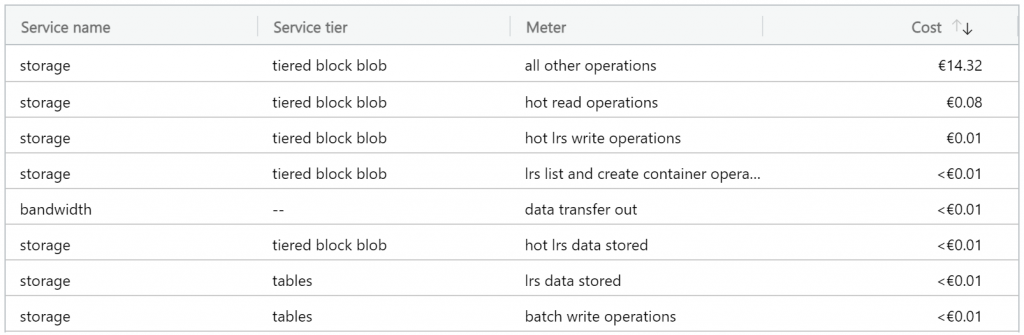
What I did when I was estimating my Azure storage costs was blob reads and writes. Most of the numbers in this table were roughly where I had estimated them to be (a bit lower, even) but what made absolutely no sense here is “all other operations”. What is other operations?
When “other costs” is 160x all the itemized costs combined
After some research, I still didn’t know what exactly “other operations” are, but at least I figure out a way how I can see the exact number of Azure Storage blob API calls – per call! First, I took a look at the metric, and the chart looked like this:
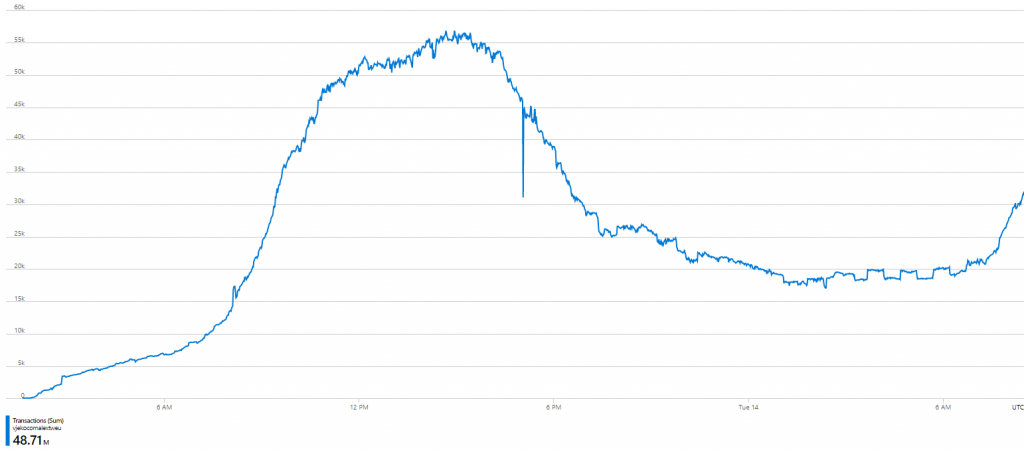
Few things were clear. First, I’ve made 48.71 million of blob API calls in this period. Second, at the peak (which is around 3PM CET) I was approaching 60 thousand calls per minute.
But now into individual call types. I expected read and writes to not be this crazy. And they weren’t, just like I expected (this is sum of reads and writes for the same period):
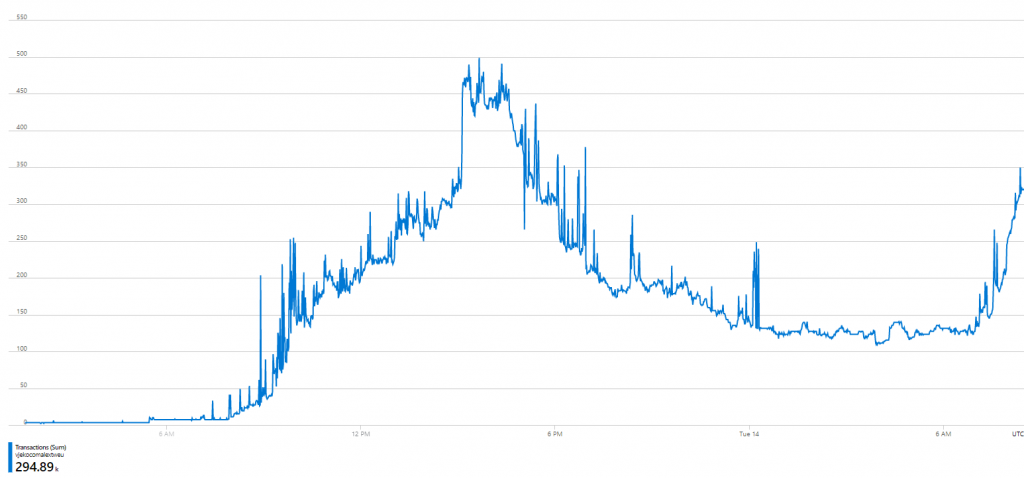
Now, this made sense, and these numbers totally correspond to what I’d expect from AL Object ID Ninja to generate. At its peak, it was reaching 500 read/write calls per minute. But this was 295 thousand calls. What were the other 48.42 million? 😐
Call type by call type, I’ve found this:
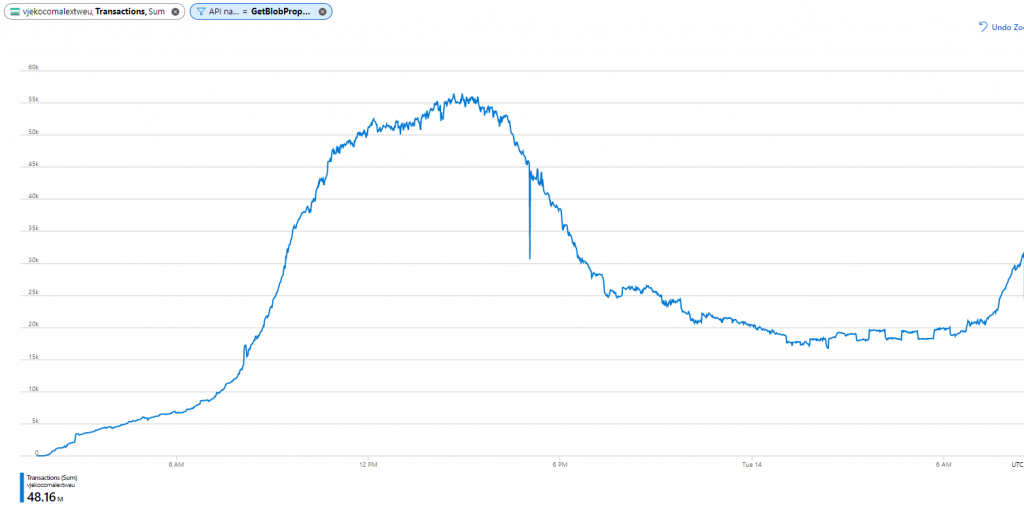
So – the culprit was… GetBlobProperties.
In short, apparently my back end was calling GetBlobProperties up to 55 thousand times per minute. If I knew one thing about my back end, it’s that I’m never, ever, ever, ever calling GetBlobProperties. I checked my code once more, to make sure. And I made sure. No, I was right. No GetBlobProperties.
Something was doing it for me. How nice of something. And how in the earth am I going to figure it out?
The worst of all was this: if I don’t figure this out, and quickly, and then sort it out, by Sunday I’d be calling quits on AL Object ID Ninja and I would have to stop maintaining a free back end, you’d all have to maintain your own back ends. Bye-bye zero configuration dream.
And, what was obvious from the chart, AL Object ID Ninja was warming up for the next day. While it had 1,750 downloads at 3PM on Monday, it started Tuesday with 2,300 downloads, so if anything I could expect these numbers to go up. Way up.
Why I Hate Frameworks
My first course of action was to figure out where those GetBlobProperties calls come from. If my code isn’t making them directly, then something else that I call must be calling them heavily. And by heavily, I mean H.E.A.V.I.L.Y. To be precise, for each read or write call, there are ~120 GetBlobProperties calls, for all I could tell.
First I went on and analyzed Azure blob API for Node.js. That’s the API I was using, and I wanted to know which of the two operations I am using is causing the problem. The blob API did indeed have several places where GetBlobProperties was called, but they were few and far between. And there certainly wasn’t a single function that invoked it more than once. To make it worse, the read method I used didn’t ever involve GetBlobProperties, and write method I used was invoking it once. However, not only I did far less write operations than read operations, if GetBlobProperties was invoked by my write operation (and it was – once, per source code) it would have to be around 12,000 GetBlobProperties calls for a single write operation.
That wasn’t it.
There was only one more thing that could cause it, and that’s what I call declarative blob bindings. Azure documentation calls them Azure Blob storage input binding for Azure Functions.
It’s this thing:
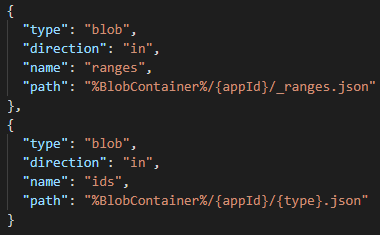
This kind of binding allows you to make blob storage available to your code without you having to write a single line of code. An input binding allows you to map a blob to a property in context.bindings and in the example above, I would have two properties ready for me in my JavaScript code: context.bindings.ranges (containing the array of ID ranges) and context.bindings.ids (containing the array of consumed IDs). I mean, beautiful, so simple.
And so freaking expensive!
Since I was 100% positive that my explicit blob code didn’t cause those 48 million GetBlobProperties calls – my suspicion was that it was the declarative binding. I didn’t have proof for this, only hunch. I could prove it by looking at Azure Functions Node.js runtime code, but that would take me far too much time, and I realized I’d be much faster if I replaced declarative binding with explicit blob reads.
I also took it for granted that the #1 source of those calls was the getLog API which was invoked every 15 seconds by every instance of AL Object ID Ninja – for the purpose of showing notifications. I knew from day 1 that polling is a bad idea, but I really wanted to have this feature out right from the start, and I knew always I will soon replace it with some push technology, but my estimates showed me that even with 15 second polling interval, the costs should be acceptable, even with maximum number of estimated users.
So, if I wanted to see for a fact if declarative bindings were causing this vast volume of GetBlobProperties calls, getLog was the place to start. That function declared to input bindings:
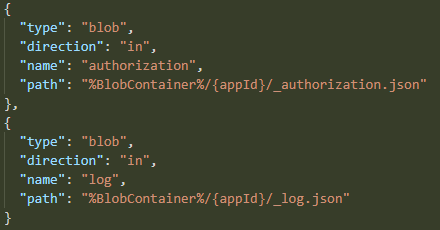
After a short while, when I refactored it (commit 6e10612). I removed authorization binding from all functions, any unnecessary bindings from any functions that had them, and both bindings from getLog. Now getLog was not making any implicit calls to whatever API it does, and it only does one read of _authorization.json and one read of _log.json per operation, and none of these should do any of GetBlobProperties.
Good.
So I deployed the back end (there was some 15 seconds downtime around 11AM CET (sorry, anyone who was attempting to assign an ID at that moment). And then just as Azure was warming up for another day of gluttony, the chart showed this:
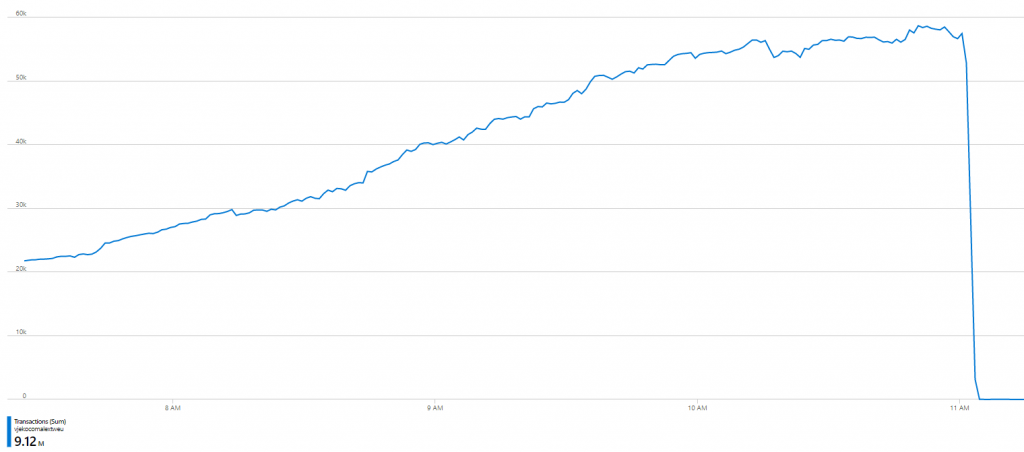
I mean… what the heck! Not down by half, or third, or something. Down to ZERO. Near zero. I mean, this was GetBlobProperties consumption from that moment on until the end of the day (when zoomed in):
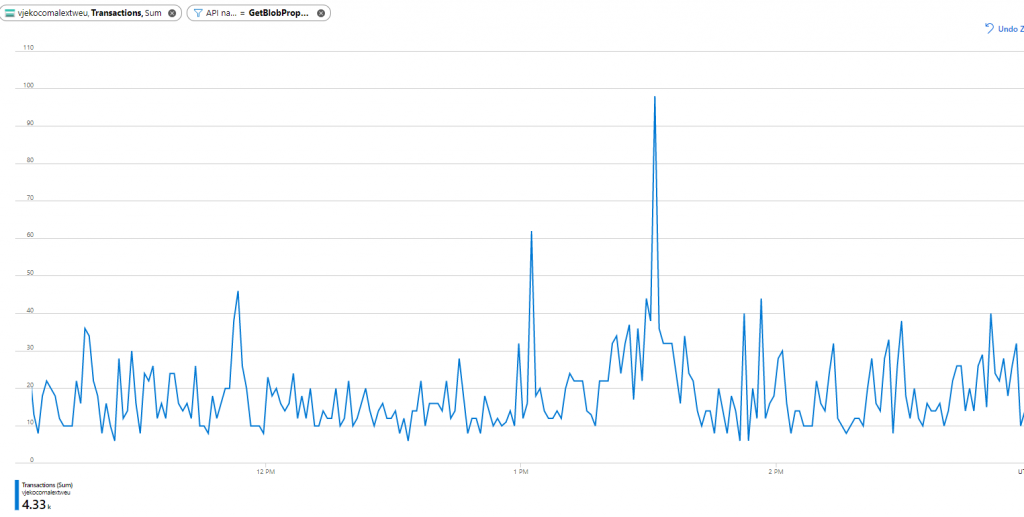
So, from ~60,000 per minute down to ~60 per minute. A 1000x reduction in the number of GetBlobProperties calls.
Lesson learned – unless you are ready to spend crazy money on “other” blob costs, don’t be lazy and use declarative binding. Just read blobs explicitly when you need them.
In my particular example, I don’t even need both _authorization.json and log.json blobs. I only need log.json if authorization succeeds. Which I believe it does most of the time, but still. Having control of things is better than not.
And now to why I hate frameworks. I don’t really hate frameworks, I love them. But what I hate about most frameworks is that they are bulky. And they often do far more than what you really need from them. And they are very often very inefficient at certain things which they do just in case. I can’t really say why I had roughly 120 calls to GetBlobProperties when I declaratively bind a blob, if I had 0 calls to it I explicitly read that blob. Okay, I’d agree that maybe 1 call was enough. Whatever this declarative binding was doing, it was amazingly inefficient at that.
Just as a small digression here, and another example of me taking things in my own hands rather than picking a framework off a shelf. When synchronizing object IDs I have to parse all AL file in the entire repository. Most other AL extensions do regular expressions. I mean, regular expressions are *the* way of analyzing text content and figuring out if it has what you are looking for. But first, writing a regular expression that can properly parse syntax in all situations is near impossible, and second, even if you do it, it will be very slow. I ended up writing my own parser for what I needed out of AL files, and it’s able to process 3,000+ AL files in under 300 milliseconds. With 100% reliability. Take that, regex!
It’s not the end yet
But this is not the end of it. I did get rid of my GetObjectProperties calls, but I tremendously increased my blob reads. When checking the chart of everything going on, I got this:
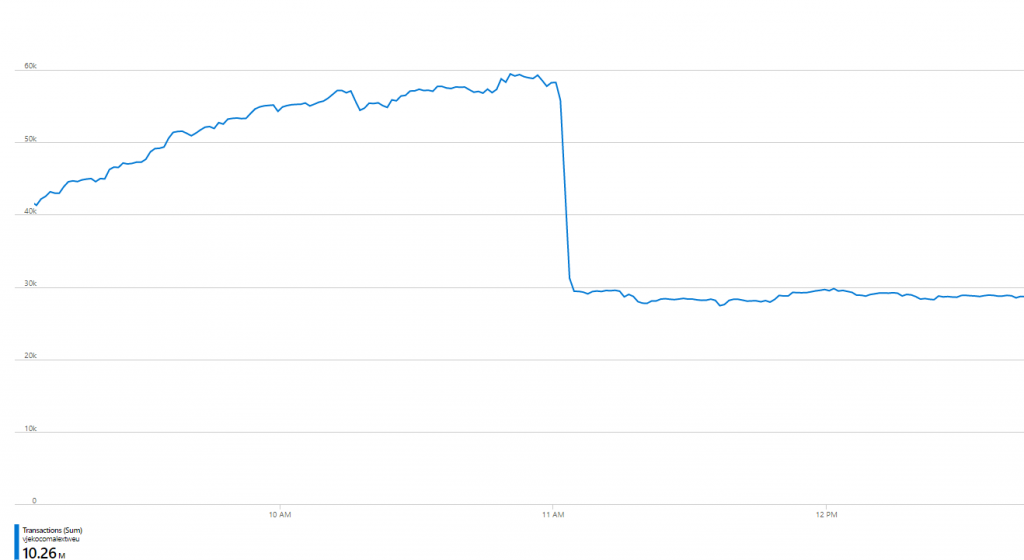
In short – I’ve cut total number of operations in half, but I still didn’t reduce the cost substantially. After all, blob reads cost exactly as blob “other operations”. And worst of all – the numbers still didn’t make sense – I was hitting 30K operations per minute, which would mean 7,000+ users working in it concurrently! That was impossible, I only had ~2,500 downloads of AL Object ID Ninja at that time.
There were two problems here. First is that the number of blob operations is still huge, and most of those operations read exactly the same content. I mean, if you assign – on average – 3 object IDs per day, and bombard the back end every 15 seconds to tell you that, and for each of those calls you read exact same authorization and exact same log, that’s absolutely crazy. The second is – there were nowhere near 7,000 users, so one of the following must be true:
- There is some inefficiency in Ninja itself 😲; or
- Somebody built their own copy of Ninja and changed the polling interval from 15 seconds to something like 500 milliseconds 😨; or
- Somebody is intentionally flooding my back end with calls in order to bring it down 😨😨
In any case, not good.
First things first, I decided to not read authorization file on every call. That was insane. I mean, authorization is mostly set once for the life of an app, so why read it every freaking time? My next commit (77d879) was about caching authorization. And then I decided to drop the log.json altogether and keep logs entirely in memory. When you assign an ID, back end stores it in volatile memory, and when anyone asks for log, it serves it from memory. That was the next commit (fe707c).
The way authorization is cached has a known “vulnerability”. I mean, it’s not really vulnerability, it’s just a small glitch that under very special and unbelievably unlikely circumstances, after somebody authorizes their app, for next 10 minutes it was possible for somebody to actually bypass it. It was very unlikely that they would be able to, in the first place. And that’s something that will stay there. I have no intentions to change it. I mean, first, authorization itself is most likely going to go away at some point because it’s actually pointless. There is nothing to really protect that AL Object ID Ninja exchanges with the back end. And then – if you want it secure, just take the repo, deploy it to your own Azure back end, lock it behind whatever heavy security you want, and you are safe. I’ve just decided that my free public API will do this small tradeoff. Either that, or it can’t be free.
Anyway, the authorization was cached for 10 minutes, after which time it was re-read by all instances, and I saw an instant decline in total number of blob calls:
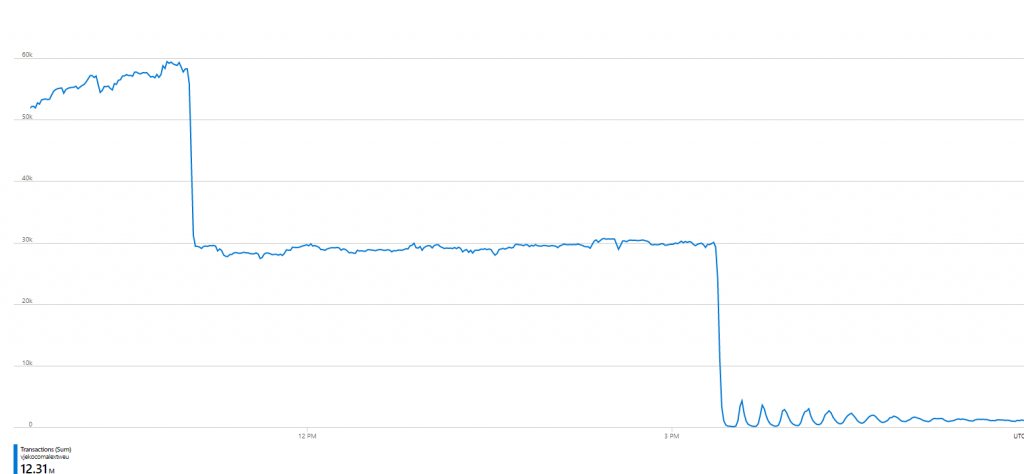
As you can see, there were those spikes every 10 minutes, as caches started refreshing, but due to volume and dynamics of calls from different repos, they flattened out eventually.
Still not the end. Geez, this is like Lord of the Rings, part three!
So, at about 3:30 PM yesterday I managed to resolve my blob issues. Whatever blob storage is going to cost me now, it’s going to be insignificant.
But I still have a big problem. The number of calls was still huge. I was serving stuff from in-memory cache, but this didn’t change the fact that I had about 7,500 total calls per minute to all endpoints. One of the two scenarios must be true: either somebody built their own version of Ninja that polls my back end every 500ms, or somebody wrote a script that bombards it thousands of times per minute.
I was aware of this potential problem from the beginning. And my train of thought was this: somebody will surely attack it at a point. But that’s not going to be immediately. I will implement a rate limiter to prevent DOS attacks, but it’s not my topmost priority.
I certainly didn’t expect it to happen this quick!
So I decided to do is implement a rate limiter (commit 5d7f98). I mean, for this service to be free for all, there must be fair use. And I obviously could not count on fair use by everyone, and I had to enforce it.
Call Rate Limits in AL Object ID Ninja
So these are the call rate limits I decided to put in place. Any IP address is allowed to place this many calls:
- 10 calls within any given 1-second interval
- 20 calls within any given 5-second interval
- 40 calls within any given 10-second interval
- 60 calls within any given 30-second interval
If you violate this, your call gets rejected. Accumulate three violations in 30 seconds, you get banned for the next 10 seconds.
You could say that the “grant” is even too forgiving. Maybe I should ban an IP address for longer than 10 seconds, maybe I should allow fewer calls per interval. But I think I am going to leave it here for a while, and then monitor how it’s being used.
The reason why I am allowing this ample allowance per IP address is that some teams may work behind a single public IP address. And then if you have a 20-person team, on average there will be 80 getLog calls every minute. That should do. If it doesn’t – talk to me! Or deploy your own back end, whichever you prefer.
Before I left work yesterday, I decided to check the rate limiter violation log. Yes, whenever a 10-second ban is given, I log the IP address, app ID hash, and the API endpoint that caused the ban. I expected to find something there, because obviously there must be one or two IP addresses that are calling it.
What I found made my jaw drop. There were thousands of bans issued within some 15 minutes, and there was no rule about IP addresses. There were note one, or two, or three different IP addresses. It was – from all I could tell – all of them!
So I dropped the limiter, when home, and decided to think about it for a while.
Obviously, it’s extremely unlikely that someone has launched a true DDOS attack against my poor Ninja, So it must be something inside Ninja itself that does it.
One thing that I checked first thing later in the evening was which endpoints were being “attacked”. All, I mean all calls are to getLog. I also analyzed the IPs and realized that very few addresses got more than two or three bans. This could mean only one thing. Ninja is not sending one call per 15 seconds per user, but *FAR* more.
And then I realized what it was before even looking at code. Ninja is sending one call per 15 seconds per user *PER ROOT FOLDER*. So, if you have a – say – 20-root workspace, Ninja would place 20 calls every 15 seconds. If you had a 2 people team running a 20-root workspace behind the same IP address – you are guaranteed to hit a ban! So, obviously the average was under 20 folders per workspace, but anyone who had two or more was a potential “attacker”.
And so the last thing before I actually called it a day yesterday was to update both the back end and the front end and make getLog not per folder, but per workspace. So if you have 100-root workspace, it will be 1 call, not 100 calls.
Just for good measure, I’ve also increased polling interval from 15 seconds to 30 seconds.
So, no matter how large your workspace is, for any fair use of AL Object ID Ninja back end, you won’t ever hit the rate limit violation ban.
Good morning, sunshine
It’s now nearly 10AM, and let’s take a look at those consumptions:
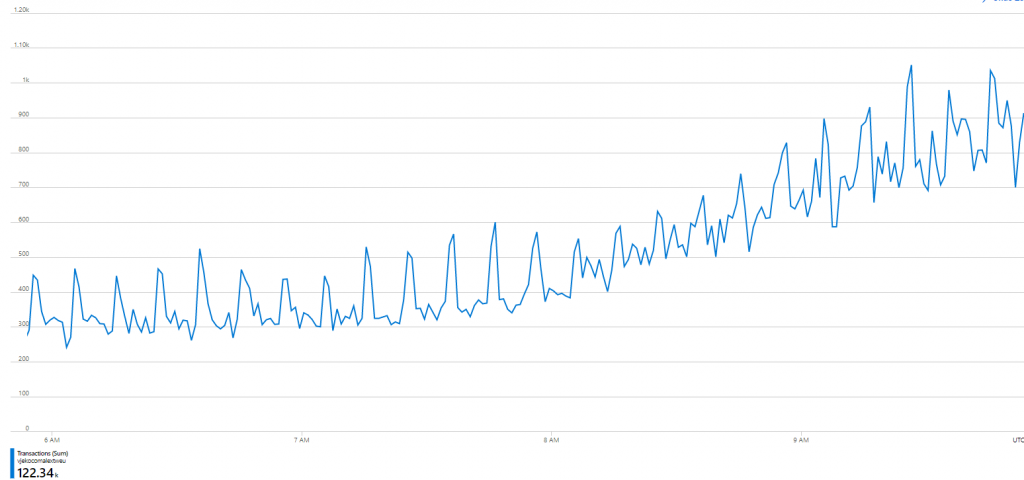
Now we are talking business! These numbers are where I’d expect them to be, the graph shows this 10-minute authorization cache refresh peaks that show a small tendency to flatten out, and the back end is warming up for another day of serving object IDs to you folks! And at the same time, I can keep it completely free for you to use!
How many of “you” are really there
Just in case you wondered, here are some numbers:
- 2909 total downloads as of this moment
- 517 total AL apps being under AL Object ID Ninja control
Not bad for the third day of production!
Thanks for bearing with me 😎
Nicely done, Vjeko! Thanks for sharing all the details. Sure appreciate all you did to make this a reality and keep it free for everyone.
If anyone want to encourage MS to remove object id’s entirely, vote for this suggestion: https://experience.dynamics.com/ideas/idea/?ideaid=7b4849dd-dd13-eb11-8441-0003ff68a0b0
Thanks, Greg! I’ve put my vote there (even though it will for sure put my Ninja out of business 😁)
I’ve discussed this with a few folks at Microsoft at several occasions, and while I have no fresh information, I wouldn’t really hold my breath anymore for them removing the IDs. I held some hopes when they released controladdin object type and there were no IDs. But then when they came with enums and they had IDs, I’ve actually lost hope. I don’t really expect them to spend any time/money into this anymore.
Hey Vjeko, I tried to install it from the marketplace but got this error:
Error while installing ‘AL Object ID Ninja’ extension.
Unable to install ‘vjeko.vjeko-al-objid’ extension because it is not compatible with the current version of VS Code (version 1.52.1).
I don’t think I have any weird version of VS Code or anything.
Hey Reinhard,
It’s not that your version is weird, it’s just old. Much as Microsoft adds things in the front end of VS Code, they add/change/remove things in its internal API too. If my extension is using any APIs that are newer than 1.52.1 – then it won’t work. And since I don’t know for a fact if it uses any new APIs (I was simply building with the APIs that I had at my disposal when I was building, not checking if they are backwards compatible) I can’t mark it as compatible with any versions I didn’t test with. That’s all.
Please, keep in mind, there is very little incentive for me to actually spend time and test with old versions. VS Code is updated monthly, most users update automatically. Making it backwards compatible takes (a lot) of time, and I only have as much time to spend with it. I’d rather spend time building new features and fixing bugs, than keeping it up-to-date with old versions. 1.52.1 is almost a year old, that’s ages in terms of software that updates every month.
Any particular reason why you are still using that version?
Awesome job here!
Thank you for this amazing tool and making all available.
Nice 429 shaming btw 😀
Thanks, I am glad you like the tool!
I am having a rocky time with an Azure app too, and there’s 100k times more calls to GetBlobProperties than anything else. This read gives me hope.